If you're building AI-powered products, you need inference: the ability to send a prompt to a model and get a response. Unless you're running your own GPUs, you're buying this from a provider.
Once you've chosen a model, you often have options for where to run it. Open-source models like MiniMax, gpt-oss, or Mistral are served by dozens of competing providers. Even proprietary models like GPT or Claude are available through multiple channels beyond their native APIs.
So you filter for the basics: GDPR compliance, data sovereignty, zero-data-retention if you need it. Then you compare prices. Provider A charges €0.27 per million tokens, Provider B charges €0.77 for the exact same model. Easy choice, right?
Not quite. The same model, literally identical weights, served by different providers can perform completely differently. Price per token is necessary, but rarely sufficient.
What Goes Wrong
Here's a story I've seen play out multiple times. A team is building an AI feature and they need to choose a provider. They compare token prices, see one charges €0.27 per million tokens and another charges €0.77, and they pick the cheaper option. It seems like an obvious decision.
Three months later, problems emerge. Users start complaining that the AI "feels slow." Agentic workflows that should complete in 2 minutes are taking 15. Long documents cause timeouts. During peak hours, quality becomes unpredictable.
So they switch providers, having wasted months of integration time and left users frustrated along the way.
The provider wasn't the problem. The problem was how they evaluated it.
Why Price Per Token Is Misleading
Look at real benchmark data. DeepSeek V3.2 across four providers:
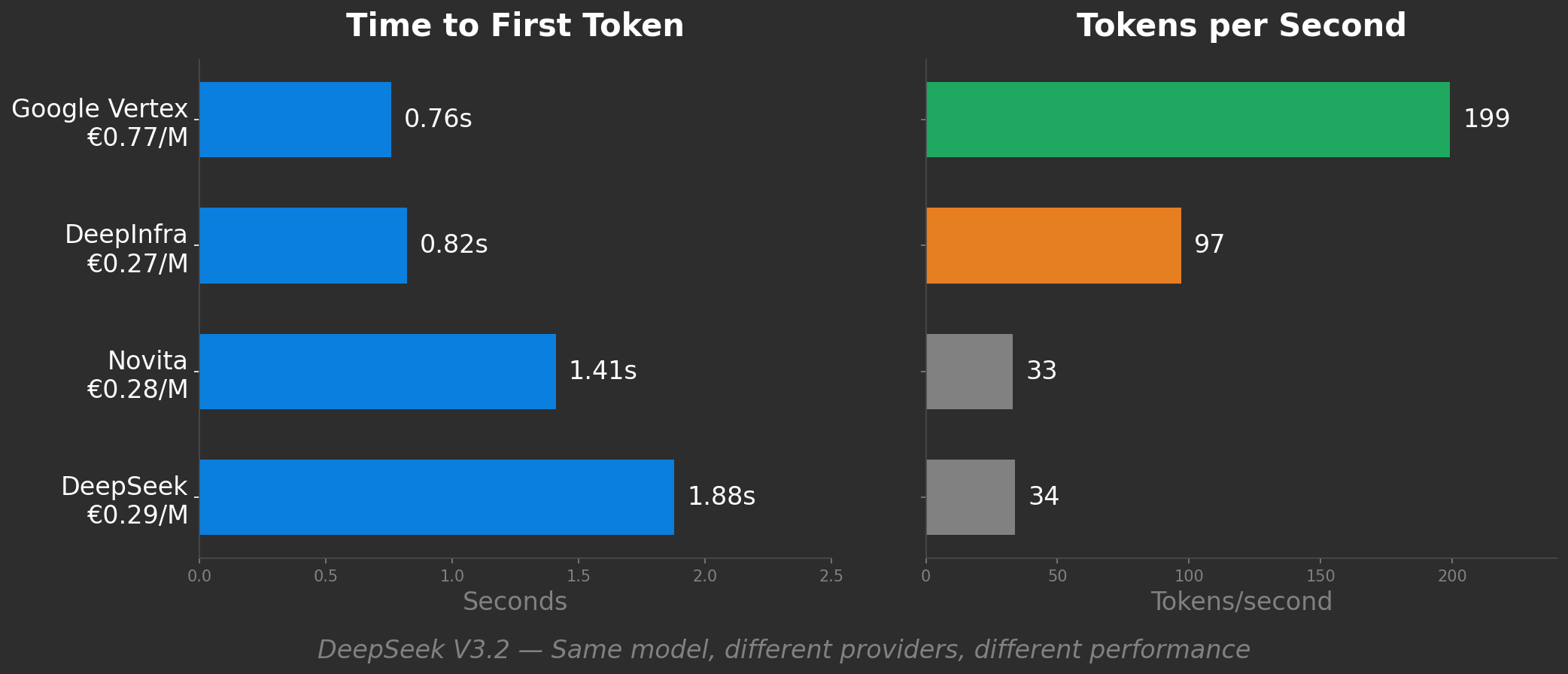
DeepInfra looks like the smart choice: half the speed of Google Vertex, but a third of the price. Novita and DeepSeek native are similarly cheap but 6x slower than Vertex.
But "price per token" doesn't tell you any of this. It treats all four as equivalent products. They're not.
What Actually Matters: Five Factors
When you send a prompt to an inference API, the provider's infrastructure takes over. Your request hits a queue, gets routed to hardware, the model processes your input, and tokens start streaming back. Five things determine how that process performs, and whether the provider works for your use case:
Time to First Token (TTFT): How long before output starts appearing? Users need to know something is happening. A 200ms TTFT feels responsive. A 2-second blank screen feels broken, even if the total response time ends up the same. Remember that TTFT includes network latency: an EU user hitting a US provider adds 100-150ms before inference even starts. And averages lie: production systems break on p95/p99 latency, not medians.
Tokens per second: How fast do tokens stream after that first one? This determines when you get the complete response. For a chat UI, users read as it streams, so tokens per second matters less. For an agentic workflow waiting on the full response before the next step, tokens per second is everything. Again, distribution matters: consistent 80 tok/s beats variable 50-150 tok/s.
If you've worked on web performance (Core Web Vitals, Lighthouse scores), you know the distinction: when something appears vs when it's usable. TTFT maps to First Contentful Paint. Tokens per second maps to Time to Interactive.
Capacity: Can the provider handle your volume? Rate limits, concurrent request limits, whether performance degrades at scale. A provider might be fast for your proof-of-concept but throttle you in production.
Context handling: Does performance hold up with long inputs? A 4K prompt and a 64K prompt are priced the same per token, but they cost the provider very different amounts to serve. Some providers slow down dramatically. Others throttle. Others charge more.
Quality: Are you getting full precision, or is the provider quietly running a compressed version of the model to save memory? Lower precision can mean subtly worse outputs, especially on hard reasoning or long-context tasks.
Every provider makes tradeoffs between these five, plus price. Optimizing for one often costs another. The question: which tradeoffs fit my workload?
Different workloads, different priorities
The right tradeoffs depend entirely on what you're building. A chatbot and a batch processing pipeline have opposite priorities. Optimizing for one would hurt the other.
A rough guide to how the five factors typically play out. Your specific use case may differ (a chatbot with very long conversations cares more about context handling than a typical one), but this gives you a starting point:
| Workload | TTFT | Tokens/s | Capacity | Context | Quality |
|---|---|---|---|---|---|
| Interactive chat | ●●● | ● | ●● | ● | ●●● |
| Batch processing | ● | ● | ●●● | ● | ●● |
| Agentic workflows | ● | ●●● | ●● | ●●● | ●●● |
| Voice AI / real-time | ●●● | ●●● | ●● | ● | ●●● |
| RAG / retrieval | ●● | ● | ● | ●●● | ●●● |
●●● = critical, ●● = matters, ● = less important
Example: agentic workflows. An agent making 50 inference calls to complete a task doesn't care much about TTFT. No human is watching between steps. But tokens per second compounds: if each call generates 500 tokens, the difference between 100 tok/s and 30 tok/s is 5 seconds vs 17 seconds per call. Over 50 calls, that's 4 minutes vs 14 minutes for the same task. Context handling also matters: agent conversations grow as they work, and providers that slow down at 32K+ tokens will bottleneck your workflow.
Once you know your workload, you can evaluate properly. But first, you need to understand why these tradeoffs exist.
Why These Tradeoffs Exist
Most inference providers run on GPUs, so the tradeoffs below reflect GPU-based infrastructure. Alternative architectures like Google's TPUs or SambaNova's dataflow chips handle some of these differently, but GPUs remain the industry baseline.
Prefill vs Decode: Two Different Problems
When you send a request to an LLM, two distinct phases happen:
Prefill (processing your input): The model reads your entire prompt and figures out how each word relates to every other word (this is called "attention"). It processes all input tokens at once, in parallel. GPUs excel at this kind of parallel work, running at high utilization.
Decode (generating output): Now the model produces output tokens one at a time. The weights sit in GPU memory, but for each token the GPU must read through them to compute the next prediction. The bottleneck is memory bandwidth, not compute. GPUs sit idle waiting for data to arrive, dropping to significantly lower utilization.
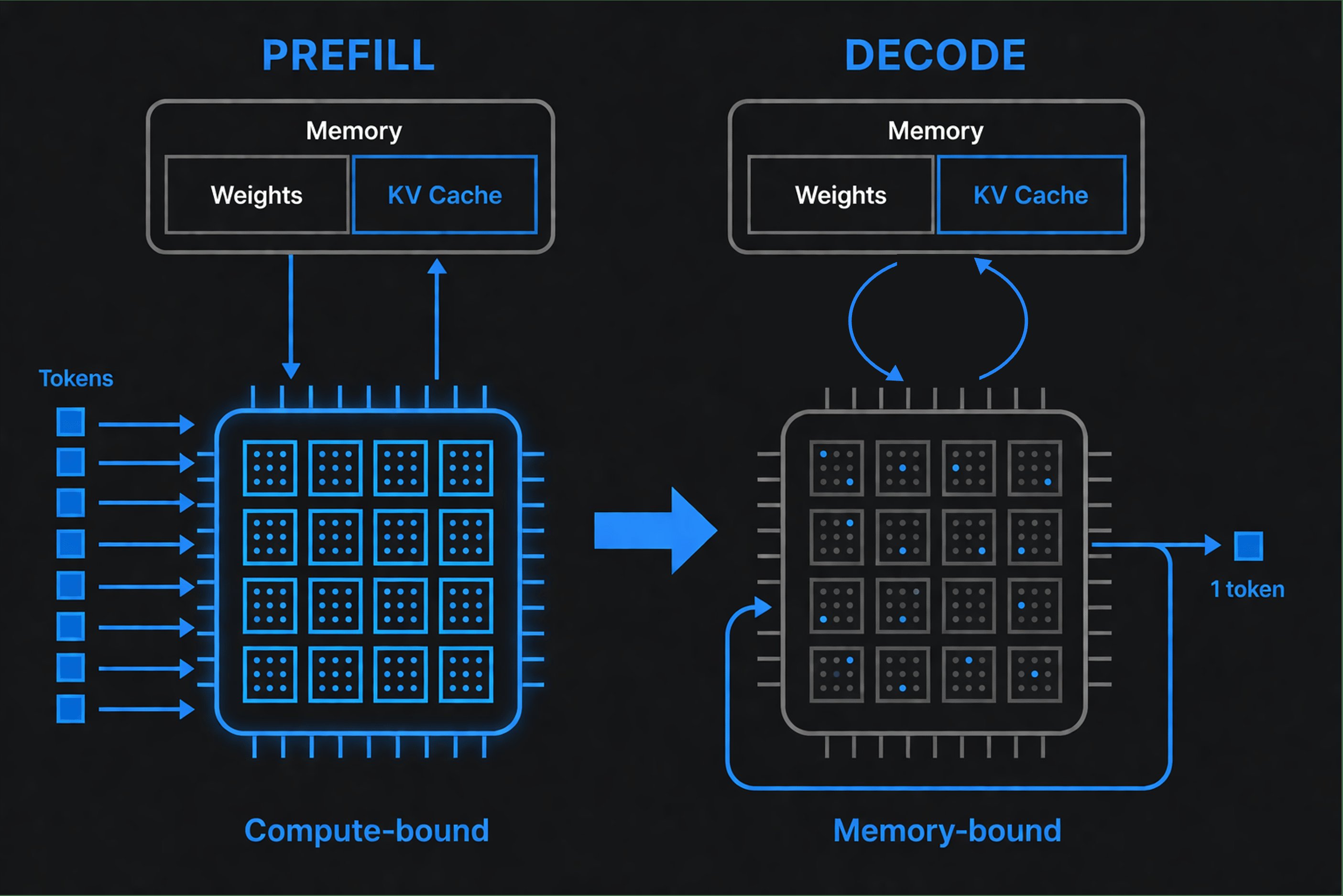
This creates two separate metrics:
- Time to First Token (TTFT): How long until output starts. Determined by prefill.
- Tokens per second: How fast tokens stream to you after that. Determined by decode.
A provider optimized for prefill shows fast TTFT but may have slow decode. One optimized for decode streams quickly but takes longer to start. Neither is "better." It depends on your workload.
Context Length: The Hidden Cost Multiplier
Most providers charge the same per-token rate regardless of context length. But the compute cost isn't flat.
Prefill scales quadratically in standard transformer attention. The model computes how every word relates to every other word. A 1,000-token prompt means 1 million relationship calculations. A 10,000-token prompt means 100 million. Double your context, attention compute roughly quadruples. (Modern optimizations like FlashAttention reduce this in practice, but the scaling pressure remains.)
Real numbers from Meta running Llama 3 405B:
- 128K tokens: 3.8 seconds prefill
- 1M tokens: 77 seconds prefill
Decode also slows with context. During generation, the model stores intermediate calculations in a "KV cache," a scratchpad of the conversation so far. This cache grows linearly with context. A 128K conversation needs ~40 GB just for the cache on a 70B model.
For each new token, the model reads this entire cache. Larger cache = more memory bandwidth consumed = slower tokens per second. And since memory is shared across users, larger caches mean fewer concurrent users.
How do providers handle this? Three ways:
- Cross-subsidize: Short-context users pay for long-context users
- Tiered pricing: Google charges 2x for context above 200K tokens
- Degrade service: Throttle or deprioritize long-context requests
If your workload is context-heavy, this matters. If it's short prompts, you might be subsidizing others.
Batching: How Providers Trade Your Tokens/s for Their Capacity
What is batching? Instead of processing one request at a time, providers group multiple requests and process them simultaneously. More efficient for the GPU. Like a bus carrying 50 people instead of 50 taxis.
At batch size 1, GPUs have low utilization because they wait on memory. At batch size 128, they load model weights once and process all 128 requests together. The provider can serve far more users. Higher capacity.
The catch: your tokens per second drops. A model delivering 400 tok/s to a single user might deliver 30-50 tok/s per user when batched with 127 others. Everyone waits for everyone. (Modern systems use continuous batching to reduce this tradeoff, but it doesn't eliminate it.)
For batch processing workloads, this is fine. You want the provider to maximize capacity; individual tokens per second doesn't matter.
For interactive workloads, this is terrible. Your user doesn't care that the system processed 10,000 requests that second. They care that their response took 3 seconds.
When a provider quotes "requests per second" or "tokens per second," ask: is that total system capacity, or the tokens per second each user experiences? They're very different numbers.
Quantization: The Precision You're Not Told About
What is quantization? AI models store knowledge as billions of numbers ("weights"). These can be stored at different precision levels, like measuring with millimeters vs centimeters. Lower precision saves memory but can degrade output quality.
| Precision | Memory Savings | Quality Impact |
|---|---|---|
| FP16/BF16 | Baseline | None (most models train at this) |
| FP8 | ~50% | Minimal (<1% accuracy drop) |
| INT8 | ~50% | Minor (99%+ accuracy preserved) |
| INT4 | ~75% | Significant on demanding tasks |
FP8 and INT8 are nearly invisible for most workloads. INT4 is where problems can emerge: research shows up to 59% accuracy loss on long-context tasks and 69.8% degradation on hard reasoning in worst cases. Impact varies heavily by task; many real-world applications see much smaller drops, but long-context reasoning is particularly sensitive.
Most providers don't advertise their quantization level. Some dynamically adjust precision based on load: full precision at 2am, quantized at peak hours. Same price, different product.
For batch processing, aggressive quantization might be acceptable. You're optimizing cost; small accuracy drops are tolerable.
For production applications, you need to know what precision you're getting.
Why Output Tokens Cost More
Most providers charge 4-6x more for output tokens than input:
| Provider | Input €/M | Output €/M | Ratio |
|---|---|---|---|
| OpenAI GPT-5.4 | €2.30 | €13.80 | 6x |
| Anthropic Claude Opus 4.6 | €4.60 | €23.00 | 5x |
| Google Gemini 3.1 Pro | €1.84 | €11.00 | 6x |
| DeepSeek V3.2 | €0.13 | €0.26 | 2x |
Source, converted at ~€0.92/$
Why? Remember the prefill vs decode difference: input processing keeps the GPU busy, output generation doesn't. The multiplier roughly reflects differences in GPU efficiency between input and output processing.
Notice DeepSeek at 2x. DeepSeek combines MoE (671B parameters, only 37B active) with sparse attention that reduces long-context compute. V4, released in April 2026, pushes this even further. The architecture changes the economics.
Input-heavy workloads (RAG, long prompts, short answers) benefit from this split. Output-heavy workloads (code generation, content creation) get hit by the 4-6x multiplier.
Evaluating Providers For Your Workload
Armed with this, you can ask the right questions.
For interactive / user-facing workloads:
"What's your p50 and p99 TTFT at my context length?"
Idle benchmarks don't matter. Ask for numbers under load.
Red flag: They only have synthetic benchmarks.
"What's your per-user tokens per second?"
Tokens per second streaming to each user, not total system capacity.
Red flag: They quote "up to" numbers or system-wide metrics.
For batch processing:
"What's your maximum sustained capacity?"
Total tokens per hour you can push through.
Red flag: They can't separate capacity metrics from per-user speed.
"What precision do you serve at high volume?"
INT4 at scale might be fine for your use case.
Red flag: They won't disclose quantization levels.
For agentic / long-context workloads:
"What's your tokens per second at 32K, 64K, 128K context?"
Agentic workflows wait for complete responses. Tokens per second at long context is critical.
Red flag: They only quote TTFT, or have no context-length breakdown.
"How does performance degrade under concurrent long-context requests?"
Long context consumes memory that could serve other users. What happens at scale?
Red flag: They don't know what you're asking about.
For voice / real-time:
"What's your end-to-end latency for speech-to-text → LLM → text-to-speech?"
Sub-500ms or it's not real-time.
Red flag: They only quote LLM latency, not full pipeline.
Why This Matters Now
The era of flat-rate, all-you-can-eat AI is ending.
GitHub recently moved Copilot to usage-based billing. Anthropic is tightening Claude subscription limits as agentic usage outpaces what flat-rate plans were built for. These application-level changes reflect the reality underneath: inference costs money, and the more tokens you consume, the more it costs to serve you. As the subsidies that funded unlimited plans fade, understanding what you're actually buying at the inference layer becomes more important, not less.
Some providers now make this explicit - Google's Flex vs Priority tiers, Amazon Bedrock's tiered pricing - acknowledging that speed itself has value. And these tradeoffs intensify with larger models: trillion-parameter models can't fit on a single GPU and require complex parallelization, making high-speed inference even harder to deliver.
The providers competing on price alone will cut corners you can't see: quantization, batching, throttling. The ones competing on the metrics that matter for your workload will charge more, and be worth it.
Stop comparing price per million tokens. Start with the five factors, and find the tradeoffs that fit your workload.
Infercom publishes real-time benchmarks at infercom.ai/performance if you want to compare these metrics yourself.
Written by Thomas Vits, with assistance from AI.
Sources
Benchmarks & Performance
- DeepInfra: DeepSeek V3.2 API Benchmarks
- MLCommons MLPerf Inference v5.0
- Artificial Analysis LLM Leaderboard
Architecture & Compute
- Meta Engineering: Scaling LLM Inference
- Prefill Is Compute-Bound, Decode Is Memory-Bound
- NVIDIA: KV Cache Offloading
- Transformer FLOPs Analysis
Quantization
- Red Hat: vLLM FP8 Benchmarks
- Red Hat: Half Million Evaluations on Quantized LLMs
- EMNLP 2025: INT4 Long-Context Degradation
- COLM 2025: Quantization Impact on Reasoning