Every inference provider talks about speed. Marketing pages show impressive numbers. But what does "fast" actually mean?
Two problems make this hard to parse. First, when one provider advertises 400 tokens per second and another boasts sub-200ms latency, they're measuring completely different things. Both claims can be true - and neither might matter for your use case.
Second, "fast" is always relative - but relative to what? When a GPU-based provider claims to be fast, they usually mean fast compared to other GPU providers. That's a reasonable baseline within their category, but it tells you nothing about absolute performance. A provider running on specialized inference hardware might deliver 5-10x the speed, making the GPU comparison irrelevant. This article breaks down the three metrics that define inference speed, explains when each one matters, and gives you real numbers to benchmark against. If you're also evaluating on price, see the companion piece: What 'Price Per Token' Doesn't Tell You.
The Three Metrics That Define Speed
When you send a request to an LLM API, the response doesn't arrive all at once. It flows in stages, and each stage has its own performance characteristic.
The full latency breakdown:
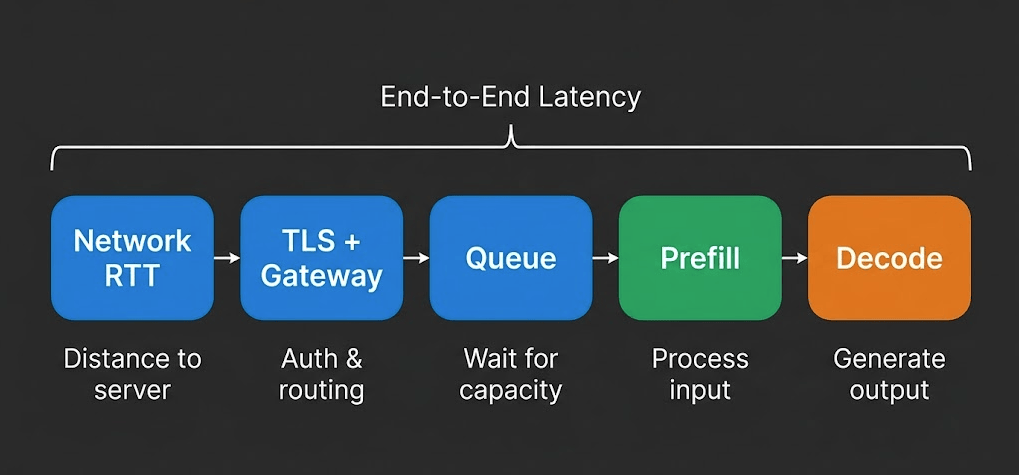
For a European developer calling a US-based provider:
- Network round-trip: 80-150ms (speed of light through fiber - no software can fix this)
- TLS handshake: 1-3 additional round trips on new connections (use connection pooling to avoid this on subsequent requests)
- Gateway overhead: 10-50ms (authentication, rate limiting, routing)
- Queue time: 0ms to seconds (depends on load and capacity)
- Prefill: varies by prompt length
- Decode: varies by output length and throughput
Prefill vs Decode - why they matter separately:
Prefill processes your entire input prompt in parallel. The model reads all your tokens at once and builds an internal representation (the KV cache). This phase is compute-bound - raw calculation speed matters most.
Decode generates output tokens one at a time. Each new token depends on all previous tokens, so it's sequential. This phase is memory-bound - the chip spends most of its time reading model weights and cache from memory, waiting for data to arrive before it can compute the next token.
Different hardware architectures handle these phases differently:
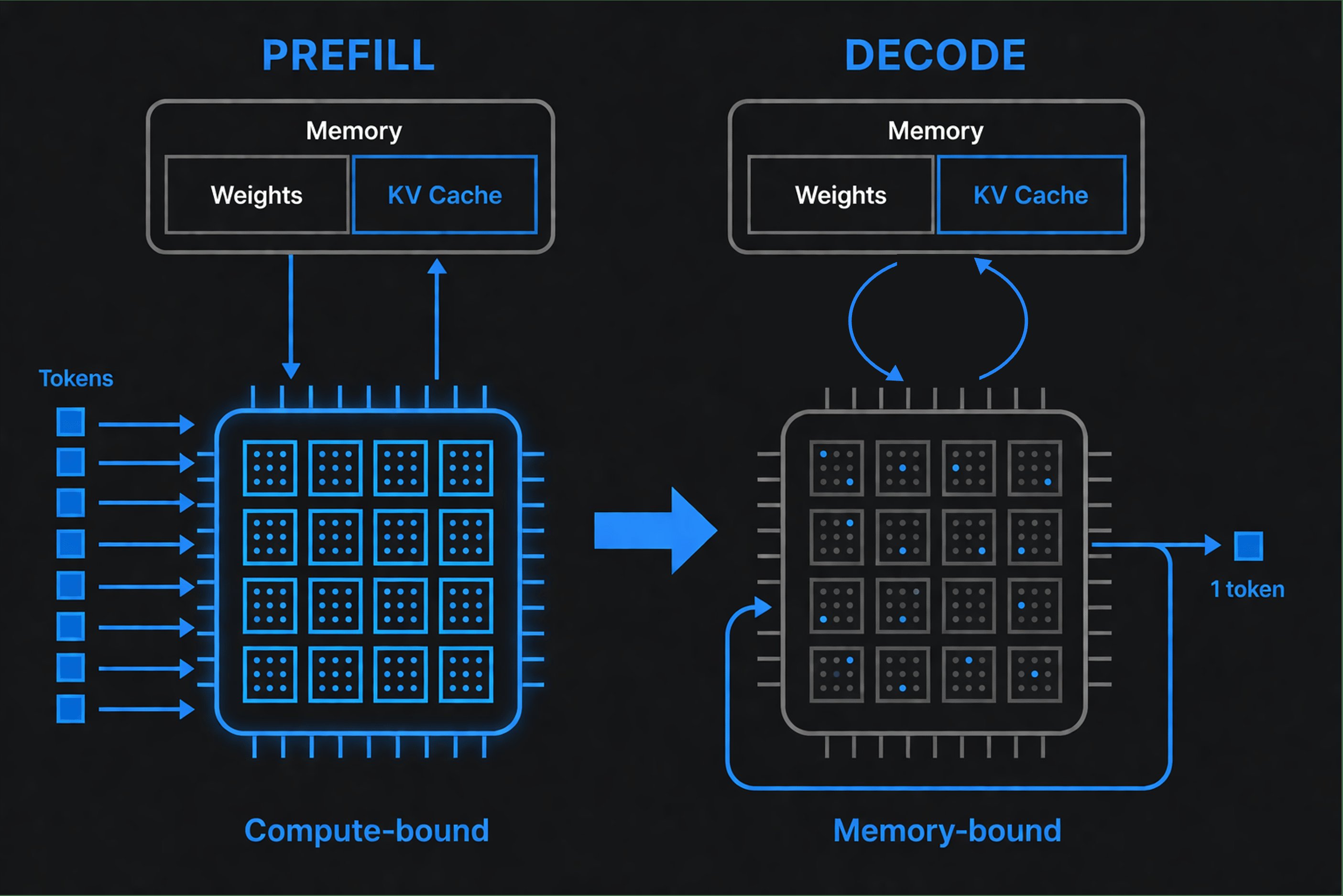
GPUs excel at prefill - parallel compute is what they're designed for - but struggle with decode. During decode, GPU utilization drops to 20-40% as the compute units sit idle waiting on memory.
Specialized inference chips like SambaNova's RDU, Groq's LPU, and Cerebras WSE are architected for the memory-bound decode phase. They keep data on-chip, reduce memory round-trips, and maintain high utilization even during sequential token generation. The result: 3-10x faster decode on large models.
That network latency hits you twice - request and response. A provider advertising 300ms TTFT from Virginia delivers 400ms+ to Munich. Before any inference happens, you've already spent 100ms on the wire.
Gateway overhead is usually small but always present. Queue time is the hidden variable - on shared infrastructure, you wait behind other customers' requests. The same API can feel instant at 3 AM and sluggish at 3 PM. Dedicated capacity eliminates contention from other customers, making performance predictable.
Time to First Token (TTFT)
TTFT measures the latency from when you send a request to when the first token starts streaming back. It determines perceived responsiveness. A 200ms TTFT feels instant. A 2-second blank screen feels broken, even if the total response time ends up the same.
For short-to-medium prompts around 1K tokens, anything under 300ms feels excellent for interactive chat. Between 300-600ms is acceptable for most applications. Once you cross 600ms, users start noticing the delay. Over a second and they'll assume something is wrong.
But TTFT scales with input length, and this is where benchmarks get misleading. A 100-token prompt might return in 200ms. A 10K-token prompt takes longer to prefill - expect 400-800ms even on fast infrastructure. A 100K-token prompt? Multiple seconds is normal. TTFT benchmarks without input length are meaningless. "300ms TTFT" on a short prompt is unremarkable. "300ms TTFT" on 10K tokens is impressive.
On Infercom's EU infrastructure with 10K input tokens, gpt-oss-120b achieves 388ms TTFT and MiniMax-M2.5 achieves 619ms TTFT.
Three factors drive TTFT:
- Prefill compute - the model must process your entire input before generating output, so longer prompts mean longer TTFT.
- Queue time - if the provider is overloaded, your request waits before processing even starts.
- Network latency - an EU user hitting a US provider adds 100-150ms before inference begins. Physics adds latency you can't optimize away, which is why data residency matters for performance, not just compliance.
TTFT matters most for interactive applications where a human is watching the screen: chat interfaces, coding assistants in IDEs, voice AI, anything real-time.
Output Throughput (Tokens per Second)
Throughput measures how fast tokens stream after the first one appears. It determines how quickly you receive the complete response. For a 1,000-token response, the difference between 100 tok/s and 400 tok/s is 10 seconds versus 2.5 seconds. That gap compounds with longer outputs.
Throughput depends heavily on model architecture, which makes cross-model comparisons misleading. A 70B dense model reads 70B parameters for every token. A 671B MoE model like DeepSeek might only activate 37B parameters per token - fewer active parameters means faster decode despite the larger total size. Hardware matters too: GPUs struggle with memory-bound decode while specialized inference chips like SambaNova's RDU, Groq's LPU, and Cerebras WSE are designed specifically for it. And within the same architecture, larger models are always slower - a 7B model will outpace a 70B model on identical hardware.
The only fair comparison is the same model across different providers. DeepSeek R1 671B runs at 30-80 tok/s on GPU-based providers, but SambaNova's RDU delivers 250+ tok/s - the fastest recorded by Artificial Analysis for that model. Llama 3.3 70B shows an even starker gap: 50-150 tok/s on GPUs versus 2,100 tok/s on Cerebras WSE and 1,200+ tok/s on Groq's LPU.
On Infercom's EU infrastructure, gpt-oss-120b achieves 713 tok/s (up to 772 on shorter prompts) and MiniMax M2.7 Ultraspeed delivers 428 tok/s (up to 444 on shorter prompts).
Throughput matters most when something is waiting for the complete response before acting. Agentic workflows are the clearest example - see why throughput matters for agentic coding. Batch processing, long-form content generation, any workflow where total completion time drives productivity.
End-to-End Latency
End-to-end latency is the total time from request to complete response: TTFT plus the time to generate all output tokens.
The math is simple. For a 1,000-token output at 100 tok/s with 500ms TTFT, you wait 0.5 seconds for the first token, then 10 seconds for the rest - 10.5 seconds total. At 400 tok/s with 600ms TTFT, the same output takes 3.1 seconds. The slower TTFT is more than offset by 4x faster throughput.
On Infercom's EU infrastructure with 10K input and 1K output, gpt-oss-120b completes in 1.789 seconds end-to-end. MiniMax-M2.5 takes 3.103 seconds.
End-to-end latency matters most when no human is watching the intermediate output. Batch processing pipelines, backend API calls, SLA-bound applications with total response time requirements - these care about when the job finishes, not when it starts.
Why These Metrics Conflict
Optimizing for one metric often hurts another.
TTFT vs. Throughput tradeoff:
The prefill phase (processing your input) and decode phase (generating output) compete for the same hardware resources. A provider can configure their infrastructure to:
- Optimize for TTFT: Dedicate more resources to prefill, start generating quickly, but decode slower
- Optimize for throughput: Batch more requests together, higher throughput per request, but longer queue times
This tradeoff is changing. The industry is moving toward disaggregated inference - running prefill and decode on separate, specialized hardware. GPUs handle compute-bound prefill efficiently; memory-optimized chips handle decode. At GTC 2026, NVIDIA announced this direction, and SambaNova partnered with Intel on a heterogeneous architecture: GPUs for prefill, RDUs for decode, Xeon for orchestration. Early results show 50%+ throughput gains without TTFT penalty.
For now, though, most providers still run both phases on the same hardware. The same model from different providers performs differently. Provider A charges less but has variable speed. Provider B costs more but delivers consistent performance. The underlying model is identical; the infrastructure choices differ.
Context length compounds everything:
Most providers charge the same per-token rate regardless of context length. But the compute cost isn't flat.
Prefill scales roughly quadratically with context length. The model computes attention between every token pair:
- 1,000 tokens: 1 million attention calculations
- 10,000 tokens: 100 million attention calculations
Real numbers from production systems show the impact. A 128K context prompt takes ~4 seconds to prefill on optimized infrastructure. A 1M context prompt takes ~77 seconds. Same model, same hardware - just more input.
Matching Metrics to Use Cases
Interactive chat prioritizes TTFT over throughput. Users read as tokens stream, so the first response matters most - they'll forgive slower generation if the reply starts quickly. Agentic workflows flip this: agents wait for complete responses before acting, no human watches between steps, so throughput dominates. Voice AI needs both - initial response time affects conversational flow, but speaking pace also matters. Batch processing cares almost exclusively about throughput and total completion time. RAG pipelines fall somewhere in the middle, balancing responsiveness with the retrieval latency that usually dominates anyway.
The Agentic Use Case
Agentic coding tools like Cursor, Cline, or Codex CLI illustrate why throughput dominates some workloads. A single coding task might require 50-200+ LLM calls as the agent reads files, builds context, plans an approach, generates code, runs tests, debugs failures, and iterates until done.
Each call generates hundreds of tokens. At 100 tok/s, a 300K token session - common for complex refactoring - takes around 50 minutes of inference time. At 400 tok/s, the same session takes 12 minutes. That's 38 minutes saved, the difference between staying in flow and alt-tabbing to Slack while you wait.
The Hidden Factor: Consistency Under Load
Benchmarks show peak performance. Production systems experience variable load.
What to ask providers:
- P50 vs P99 latency: The 99th percentile shows worst-case performance. If P99 is 5x higher than P50, you'll have frustrated users.
- Rate limits: Can you actually hit the speeds they advertise, or do limits throttle you first?
- Performance degradation at scale: Does throughput hold up when you're sending 100 requests/second?
Artificial Analysis publishes independent benchmarks that capture this variance. Their methodology tests providers continuously, showing not just peak performance but consistency over time.
How to Benchmark Yourself
Don't trust marketing numbers. Run your own benchmarks with your actual workloads.
Test with your real prompt lengths - performance varies significantly between 1K and 100K input tokens, and most marketing benchmarks use short prompts that flatter the results. Test your expected output lengths too, since short completions and long-form generation have different performance profiles. If you're running concurrent requests, benchmark that pattern specifically rather than testing single requests in isolation. Most importantly, test during peak hours. Off-peak benchmarks show best-case performance that you'll rarely see in production. Artificial Analysis publishes independent provider comparisons if you want a neutral baseline, but nothing replaces timing instrumentation in your own production environment.
Which Metric Matters Most?
Your workload determines the answer. If users are watching the screen, prioritize TTFT - sub-second response start feels instant. If agents are waiting for responses, prioritize throughput - faster tokens mean faster task completion. If you're processing at scale, prioritize end-to-end latency and consistency - total job completion time and predictable SLAs matter more than peak speed.
Most production applications need acceptable performance across all three. Blazing throughput with 3-second TTFT will frustrate interactive users. Instant TTFT with 50 tok/s throughput will bottleneck agentic workflows. The tradeoffs are real.
Test it yourself: benchmark.infercom.ai lets you run your actual prompts against our infrastructure. Or see our published benchmarks for standardized comparisons.
Why We Call It "Ultraspeed"
This is why we brand our MiniMax M2.7 as Ultraspeed:
- SambaNova dataflow architecture. Purpose-built inference hardware, not repurposed GPUs. The RDU eliminates the memory bottleneck that limits GPU throughput. How dataflow delivers speed
- 428 tokens per second. Measured throughput that makes agentic workflows practical. At this speed, a 50-step coding task that would take an hour on standard GPU infrastructure completes in minutes.
- 690ms TTFT on 10K input tokens, below 150ms on short prompts. Measured from Germany to our Munich infrastructure - EU users get the latency advantage without 100ms+ network penalty to US datacenters.
Ultraspeed is shared infrastructure - you benefit from the architecture and EU hosting, but queue time varies with platform load like any shared service.
Need guaranteed capacity? Our Dedicated Rack offering provides your own SambaNova infrastructure with no contention from other customers - predictable performance for mission-critical workloads.
The Bottom Line
Speed claims without context are meaningless. Always ask: which metric, what input length, what baseline? "Fastest LLM API" could mean fastest TTFT on short prompts, highest throughput on a specific model, or lowest end-to-end latency under ideal conditions. Without that context, the claim tells you nothing.
Your workload determines which metric matters. Interactive applications need fast TTFT. Agentic workflows need high throughput. Batch processing needs consistent end-to-end latency. Most production systems need acceptable performance across all three.
Consistency under load matters as much as peak performance. A provider that delivers 400 tok/s at 3 AM but 150 tok/s during business hours isn't actually a 400 tok/s provider for your production workload.
Network latency is physics, not software. For EU users, an inference provider in Munich will always be faster than one in Virginia - no amount of optimization can overcome the speed of light. Data residency isn't just about compliance; it's a performance advantage.
Sources
- LLM API Latency Benchmarks 2026 - Kunal Ganglani
- Time to First Token (TTFT) - IBM
- Tokens Per Second: LLM Speed Benchmark Guide - Morph
- SambaNova - Artificial Analysis
- Inference Speed or Throughput? With RDUs - SambaNova
- Key metrics for LLM inference - BentoML
- Cerebras Llama 3.1 405B at 969 tokens/second
Written by Thomas Vits, with assistance from AI.