Infercom delivers 713 tokens per second on gpt-oss-120b and 428 tok/s on MiniMax M2.7 Ultraspeed from our EU infrastructure. You can reproduce these numbers with our open-source benchmark tool.
But speed claims are meaningless without understanding why.
We're hardware agnostic. Our job is to evaluate inference architectures and deploy the best option for each workload. For memory-bound decode on large models, we currently run SambaNova's dataflow architecture because it addresses the memory bottleneck that limits GPU inference. This article explains the technical reasons behind that choice - see our technology overview for deployment details.
The Decode Bottleneck
To understand why some inference is faster than others, you need to understand what happens when you send a prompt to an LLM. Two distinct phases occur, and they stress the hardware in completely different ways.
Prefill processes your entire input prompt. The model reads all your tokens at once and figures out how each word relates to every other word - what's called "attention." All input tokens are processed in parallel, which is exactly what GPUs were designed for. Thousands of cores stay busy, utilization runs high, everything works as intended. Prefill also builds the KV cache - a memory structure that stores intermediate attention calculations so the model doesn't have to recompute them for every new token.
Decode generates output tokens one at a time. Each new token depends on all previous tokens, so the work is inherently sequential. For each token, the model must read the active weights from memory, read the entire KV cache, compute the prediction, then add the new token's data to the cache. The compute is fast relative to the memory access - the time goes mostly to waiting for data to arrive.
The KV cache is larger than most people realize. For a 70B dense model like Llama at BF16 precision, it grows at about 0.3 MB per token. An 8K context conversation needs 2.5 GB just for the cache. At 32K context, that's 10 GB. At 128K, the cache alone hits 40 GB. Every token you generate requires reading this entire cache from memory.
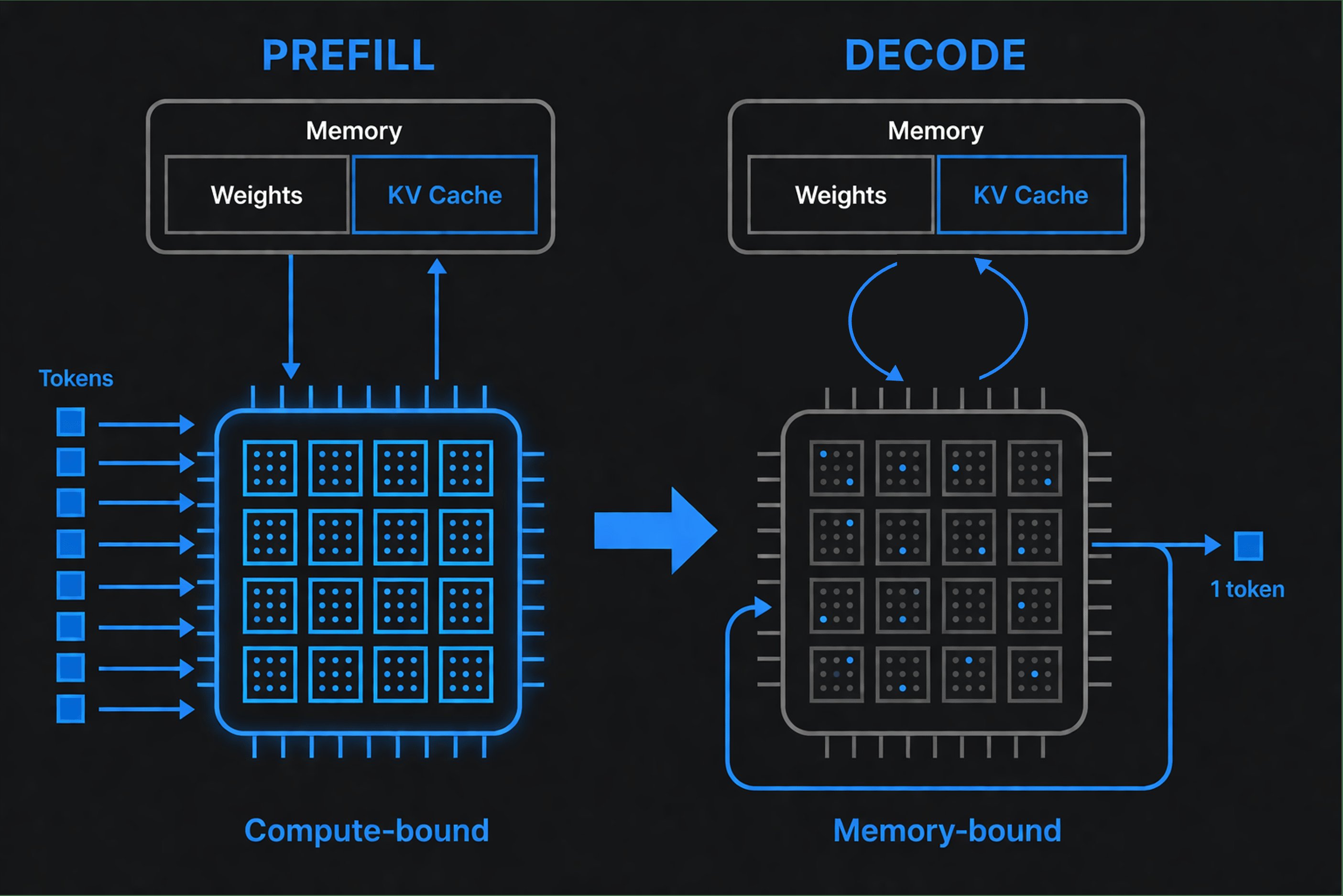
During prefill, GPU utilization runs at 80% or higher. During decode, it drops to 20-40%. The compute units sit idle, waiting on memory. This is the decode bottleneck - not a software problem you can optimize away, but a fundamental mismatch between GPU architecture and the workload. GPUs were designed for graphics rendering - massively parallel matrix math that happens to work well for training neural networks. But inference, especially sequential token generation, is a different problem entirely.
Why Memory Bandwidth Limits GPU Inference
For each output token, the model must read the active weights from memory, read the entire KV cache, compute the prediction, and update the cache. For dense models, this means reading all parameters. For Mixture of Experts (MoE) models - now the dominant architecture - only a fraction activates per token: DeepSeek V4-Pro has 1.6T total parameters but activates just 49B per token, reducing the weight reads dramatically. But the KV cache still grows with context length regardless of architecture.
Let's do the math on a dense 70B model to see the bottleneck clearly. The actual computation is trivial - 70B parameters means about 140 billion floating point operations per token, and an H100 GPU delivers 2,000 TFLOPS. The math takes roughly 0.07 milliseconds.
But reading those 70B parameters from memory takes much longer. H100 HBM3 bandwidth is 3.35 TB/s. At FP16, 70B parameters equals 140GB. Reading them takes about 42 milliseconds.
The GPU is compute-bound for 0.07ms and memory-bound for 42ms per token. A 600x difference.
This is why raw TFLOPS don't predict inference speed. When providers show you GPU specs, they're showing you compute power. But for decode, memory bandwidth is the bottleneck. Real-world numbers confirm this: production GPU inference on 70B models typically achieves 50-150 tok/s. Theoretical compute would allow 14,000+ tok/s. The gap is memory bandwidth waiting.
How Dataflow Architecture Changes the Equation
The solution isn't faster GPUs - it's different architecture. Several vendors have built chips specifically for inference: SambaNova's RDU (Reconfigurable Dataflow Unit), Groq's LPU (Language Processing Unit), and Cerebras WSE (Wafer-Scale Engine). Each takes a different approach to solving the memory bottleneck.
We chose SambaNova's dataflow architecture for our EU infrastructure (8 racks, 128 chips in Munich) because it handles large models efficiently without requiring hundreds or thousands of chips. What follows explains specifically how dataflow works and why it matters for inference.
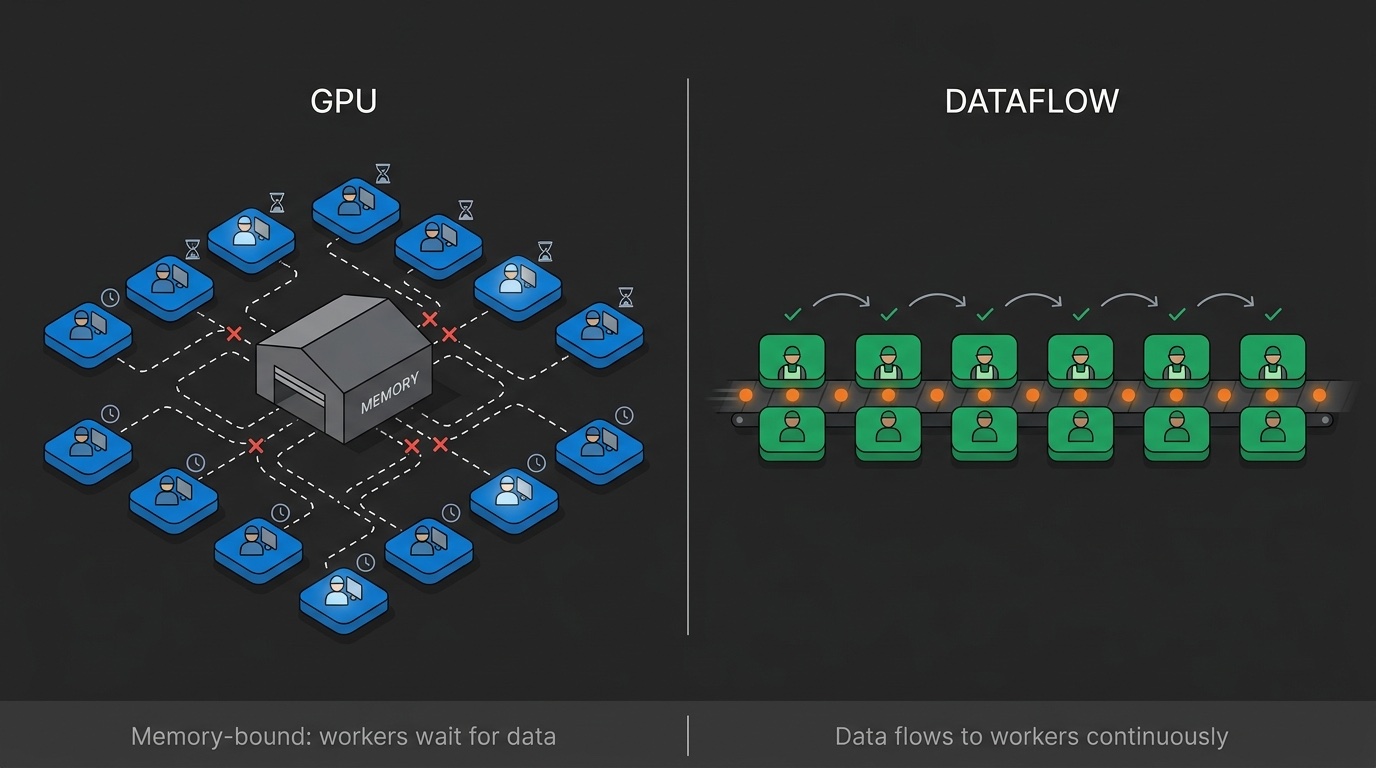
Three architectural differences explain why dataflow beats GPUs for inference:
1. Assembly Line vs. Job Shop
Think of a GPU like a job shop. Each worker (compute core) picks up a task, walks to the warehouse (memory) to get materials, does the work, walks back to store the result, then picks up the next task. Thousands of workers, but they spend most of their time walking to and from the warehouse.
Dataflow architecture works like an assembly line. Instead of workers moving to materials, materials flow through stationary workstations. Each operation is physically laid out on the chip, and data streams from one to the next without detours to memory. The chip is designed so that by the time one operation finishes, its output is already arriving at the next operation.
SambaNova calls this "spatial execution" - the computation is mapped onto the physical chip layout rather than scheduled as a sequence of instructions. The result: data keeps moving instead of waiting.
2. Three Levels of Storage, Strategically Placed
Memory speed varies by distance from the processor. The closest memory (SRAM, on the chip itself) is 100x faster than the next level (HBM), which is still much faster than system memory (DDR). The trick is keeping the right data in the right place.
SambaNova's RDU uses all three tiers deliberately. SRAM on the chip handles the hottest data - intermediate calculations that would otherwise bounce to memory and back. HBM (1 terabyte per rack) stores model weights and the conversation cache. DDR (12 terabytes per rack) holds multiple models and cached prompts for instant switching.
The key difference from GPUs: the RDU's memory hierarchy is software-controlled, not hardware-managed. The compiler decides what goes where, rather than relying on cache prediction. For predictable workloads like inference - where you know exactly which weights you'll need in which order - this eliminates cache misses.
This also means no need for quantization. GPU providers often compress models to INT8 or INT4 to reduce memory bandwidth requirements - trading accuracy for speed. The dataflow memory hierarchy solves the bandwidth problem directly, so models run at their native precision without compromise.
This design also lets a single rack run massive models. Running a 671B parameter model on GPUs requires 40 racks (320 GPUs). SambaNova runs it on one rack with 16 RDUs because the memory hierarchy scales efficiently.
The DDR tier enables another advantage: fast model switching. Because DDR is directly connected to the chips (not accessed through system memory like on GPUs), loading a different model takes milliseconds rather than the seconds or minutes required on GPU infrastructure. A single rack can host multiple models and switch between them on demand.
3. Planned Route vs. GPS Recalculating
GPUs make scheduling decisions at runtime. The hardware constantly juggles which threads run where, manages conflicts when multiple cores need the same data, and coordinates synchronization points. This flexibility is valuable for unpredictable workloads - but inference isn't unpredictable. You know the model architecture. You know the sequence of operations. The only variable is the input data.
The RDU compiler exploits this predictability. It pre-plans the entire execution - which chip handles which layer, when data moves between chips, even the exact clock cycle each operation starts. No runtime decisions, no coordination overhead, no waiting for stragglers. Think of it as the difference between a delivery driver following turn-by-turn GPS (recalculating constantly) versus an Amazon warehouse robot following a pre-optimized route through the facility. When you know the layout doesn't change, planning beats improvisation.
4. Continuous Pipeline vs. Stop-and-Go
Traditional GPU inference runs as a series of discrete operations. Launch the attention calculation. Wait for it to finish. Write results to memory. Launch the next operation. Read results from memory. Repeat. Each handoff between operations costs time - not for compute, but for memory writes, kernel launches, and synchronization. On a long inference generating hundreds of tokens, these handoffs add up.
Dataflow execution fuses operations into continuous pipelines. Data flows from attention to feedforward to the next layer without stopping. Intermediate results stay on-chip instead of making round trips to memory. The execution looks less like a relay race (hand off the baton, wait, run) and more like a river (continuous flow through a series of processing stations).
Real-World Performance Numbers
These architectural differences translate to measurable speed advantages. Artificial Analysis, which benchmarks providers independently, consistently measures SambaNova among the fastest inference providers - with gpt-oss-120b hitting 685 tok/s and MiniMax M2.7 at 426 tok/s in their live benchmarks.
On Infercom's EU infrastructure running the same RDU architecture, we see 713 tok/s on gpt-oss-120b (up to 772 on shorter prompts) and 428 tok/s on MiniMax M2.7 Ultraspeed. Time to first token on 10K input runs 388ms for gpt-oss-120b and 690ms for MiniMax M2.7 Ultraspeed. These numbers come from our EU datacenters in Munich - no US routing latency for EU users.
How does this compare? GPU-based providers typically achieve 50-150 tok/s on large models. The 3-10x speed difference reflects the architectural advantage directly - and the gap widens as models grow, because memory bandwidth becomes more of a bottleneck. For more on what these metrics mean and when each matters, see LLM Inference Speed Explained.
The Decode Era: Why This Matters Now
For years, AI infrastructure conversations centered on compute power. More TFLOPS, bigger clusters, faster training runs. That made sense when the dominant challenge was training larger models. But inference - especially agentic inference - changes the problem entirely.
Agents don't just answer a prompt and stop. They reason across long contexts, generate many tokens, call tools, iterate. Every token generation re-enters the same decode cycle. Inefficient data movement compounds latency token by token. Faster tokens translate into more intelligence because the system can explore more reasoning steps within the same wall-clock budget. This is why speed matters so much for agentic coding.
Energy Efficiency: A Side Effect of Better Architecture
Faster inference per watt isn't just a sustainability talking point. It affects operational economics directly. Infercom's SambaNova racks draw about 10 kW each. Equivalent GPU infrastructure runs 40-50 kW or more per rack - four to five times the power for comparable inference capacity. The RDUs also use standard air cooling, while high-density GPU deployments often require liquid cooling infrastructure that adds cost and complexity.
Stanford's Hazy Research lab developed a methodology for measuring "intelligence per watt" - useful output per unit of energy consumed. By this metric, dataflow architecture delivers up to 5x more intelligence per joule than GPU-based inference.
This efficiency comes from the same architectural decisions that enable speed. Keeping data on-chip reduces memory traffic. Reduced memory traffic means less energy spent moving data. Static scheduling eliminates wasted cycles. It all compounds.
What's Next: Disaggregated Inference
The industry is responding. The next evolution is already underway: disaggregated inference, where prefill and decode run on entirely separate hardware.
The logic is straightforward. Prefill is compute-bound - it benefits from raw TFLOPS and high parallelism. Decode is memory-bound - it needs bandwidth and low-latency memory access. Running both on the same chip means one phase is always suboptimal. Why compromise when you can specialize?
At GTC 2026, Jensen Huang announced NVIDIA is moving toward disaggregated inference. SambaNova and Intel announced a similar architecture: GPUs handle prefill (building the KV cache), RDUs handle decode (fast token generation), and Xeon CPUs manage orchestration and tool execution.
This matters even more for agentic workloads. When an agent reasons through a complex task, it might iterate dozens of times - reasoning, calling tools, validating results, repeating. Each iteration hits the decode phase. Latency compounds across iterations. A 3x improvement in decode speed doesn't just make individual responses faster; it enables more reasoning steps within the same wall-clock budget.
This isn't theoretical - the efficiency gains are too significant to ignore. Expect disaggregated inference to become standard for high-performance deployments over the next years.
The Bottom Line
GPU inference hits a wall on large models because decode is memory-bound, not compute-bound. The chip sits idle waiting for data. Dataflow architecture solves this with spatial execution, tiered memory, static scheduling, and continuous pipelines. The result: 3-10x faster inference on memory-bound workloads.
That's not marketing. It's physics.
The decode bottleneck isn't going away - if anything, it's getting worse as models grow and agentic workloads demand more tokens per task. The industry is responding with specialized hardware and disaggregated architectures. Infercom runs SambaNova because it delivers the best combination of speed, efficiency, and large-model support for EU deployment today. We'll adapt as the hardware landscape evolves.
You don't have to take our word for any of this. benchmark.infercom.ai lets you run your actual prompts against our infrastructure. Artificial Analysis publishes independent benchmarks across providers. Test at your typical input and output lengths. Test during peak hours. The architecture advantages show up in the numbers.
Run the numbers. That's how you know.
Further Reading
SambaNova technical resources:
- Inference Speed or Throughput? With RDUs, You Don't Have to Choose
- The Decode Era of AI: Why Dataflow Matters More Than Ever
- Solving the Decode Bottleneck: Why Agentic Inference Needs Hybrid Hardware
Independent analysis:
Infercom resources:
- Performance Benchmarks - Our actual numbers
- Technology Overview - How we deploy dataflow architecture
- LLM Inference Speed Explained - What the metrics mean
- Agentic Coding - Why speed matters for AI-assisted development
Written by Thomas Vits, with assistance from AI.