Hvis du bygger AI-drevne produkter, har du brug for inferens: evnen til at sende en prompt til en model og få et svar. Medmindre du kører dine egne GPU'er, køber du dette fra en udbyder.
Når du har valgt en model, har du ofte muligheder for, hvor du vil køre den. Open source-modeller som MiniMax, gpt-oss eller Mistral betjenes af snesevis af konkurrerende udbydere. Selv proprietære modeller som GPT eller Claude er tilgængelige gennem flere kanaler ud over deres native API'er.
Så du filtrerer efter det grundlæggende: GDPR-overholdelse, datasuverænitet, nul-dataopbevaring hvis du har brug for det. Derefter sammenligner du priser. Udbyder A opkræver €0,27 pr. million tokens, Udbyder B opkræver €0,77 for præcis samme model. Let valg, ikke?
Ikke helt. Den samme model, bogstaveligt talt identiske vægte, serveret af forskellige udbydere kan performe helt forskelligt. Pris pr. token er nødvendig, men sjældent tilstrækkelig.
Hvad går galt
Her er en historie, jeg har set udspille sig flere gange. Et team bygger en AI-funktion og skal vælge en udbyder. De sammenligner tokenpriser, ser at én opkræver €0,27 pr. million tokens og en anden €0,77, og vælger den billigere mulighed. Det virker som en oplagt beslutning.
Tre måneder senere opstår der problemer. Brugere begynder at klage over, at AI'en "føles langsom". Agentic workflows, der burde tage 2 minutter, tager 15. Lange dokumenter forårsager timeouts. I spidsbelastningstimer bliver kvaliteten uforudsigelig.
Så skifter de udbyder, efter at have spildt måneders integrationstid og efterladt frustrerede brugere undervejs.
Udbyderen var ikke problemet. Problemet var, hvordan de evaluerede den.
Hvorfor pris pr. token er misvisende
Se på reelle benchmark-data. DeepSeek V3.2 på tværs af fire udbydere:
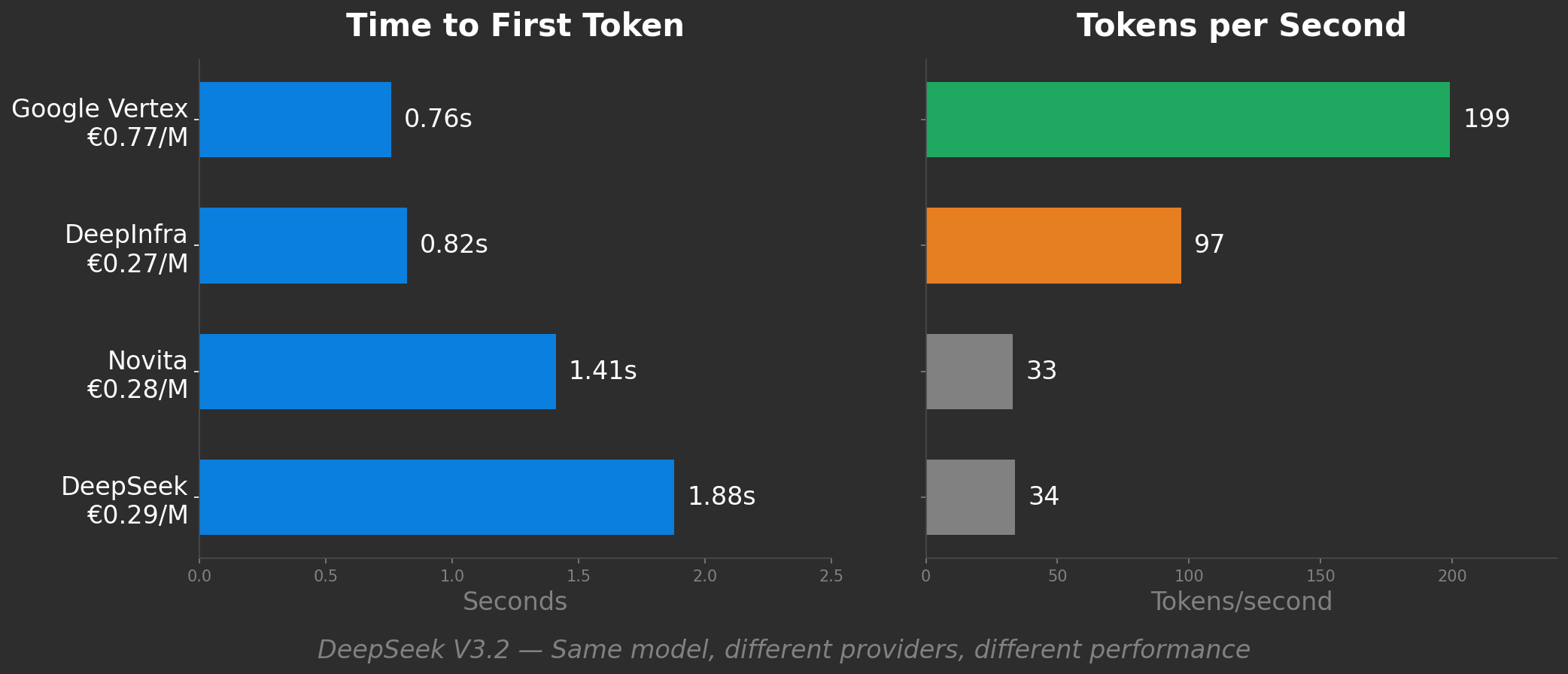
DeepInfra ser ud som det smarte valg: halvt så hurtigt som Google Vertex, men en tredjedel af prisen. Novita og DeepSeek native er tilsvarende billige, men 6x langsommere end Vertex.
Men "pris pr. token" fortæller dig intet af dette. Den behandler alle fire som ækvivalente produkter. Det er de ikke.
Hvad der reelt betyder noget: Fem faktorer
Når du sender en prompt til en inferens-API, overtager udbyderens infrastruktur. Din anmodning rammer en kø, bliver routet til hardware, modellen behandler dit input, og tokens begynder at streame tilbage. Fem ting bestemmer, hvordan den proces performer, og om udbyderen fungerer til din use case:
Tid til første token (TTFT): Hvor lang tid før output begynder at vises? Brugere skal vide, at noget sker. En TTFT på 200ms føles responsiv. En 2-sekunders blank skærm føles ødelagt, selv hvis den samlede svartid ender med at være den samme. Husk at TTFT inkluderer netværksforsinkelse: en EU-bruger, der rammer en US-udbyder, tilføjer 100-150ms før inferens overhovedet starter. Og gennemsnit lyver: produktionssystemer bryder sammen på p95/p99-latens, ikke medianer.
Tokens pr. sekund: Hvor hurtigt streamer tokens efter den første? Dette bestemmer, hvornår du får det komplette svar. For en chat-UI læser brugerne, mens det streamer, så tokens pr. sekund betyder mindre. For et agentic workflow, der venter på det fulde svar før næste trin, er tokens pr. sekund alt. Igen, fordelingen betyder noget: konstante 80 tok/s slår variable 50-150 tok/s.
Hvis du har arbejdet med web-ydeevne (Core Web Vitals, Lighthouse-scores), kender du forskellen: hvornår noget vises vs. hvornår det er brugbart. TTFT svarer til First Contentful Paint. Tokens pr. sekund svarer til Time to Interactive.
Kapacitet: Kan udbyderen håndtere dit volumen? Rate limits, grænser for samtidige anmodninger, om ydeevnen falder ved skalering. En udbyder kan være hurtig til dit proof-of-concept, men throttle dig i produktion.
Konteksthåndtering: Holder ydeevnen med lange inputs? En prompt på 4K og en prompt på 64K prissættes ens pr. token, men de koster udbyderen meget forskellige beløb at servere. Nogle udbydere bliver dramatisk langsommere. Andre throttler. Andre opkræver mere.
Kvalitet: Får du fuld præcision, eller kører udbyderen i stilhed en komprimeret version af modellen for at spare hukommelse? Lavere præcision kan betyde subtilt dårligere outputs, især på svær ræsonnering eller opgaver med lang kontekst.
Hver udbyder laver afvejninger mellem disse fem, plus pris. Optimering til én koster ofte en anden. Spørgsmålet: hvilke afvejninger passer til min workload?
Forskellige workloads, forskellige prioriteter
De rigtige afvejninger afhænger helt af, hvad du bygger. En chatbot og en batchbehandlingspipeline har modsatte prioriteter. Optimering til den ene ville skade den anden.
En grov guide til, hvordan de fem faktorer typisk spiller ud. Din specifikke use case kan variere (en chatbot med meget lange samtaler bekymrer sig mere om konteksthåndtering end en typisk), men dette giver dig et udgangspunkt:
| Workload | TTFT | Tokens/s | Kapacitet | Kontekst | Kvalitet |
|---|---|---|---|---|---|
| Interaktiv chat | ●●● | ● | ●● | ● | ●●● |
| Batchbehandling | ● | ● | ●●● | ● | ●● |
| Agentic workflows | ● | ●●● | ●● | ●●● | ●●● |
| Voice AI / realtid | ●●● | ●●● | ●● | ● | ●●● |
| RAG / retrieval | ●● | ● | ● | ●●● | ●●● |
●●● = kritisk, ●● = betyder noget, ● = mindre vigtigt
Eksempel: agentic workflows. En agent, der foretager 50 inferensopkald for at fuldføre en opgave, bekymrer sig ikke meget om TTFT. Intet menneske kigger med mellem trinene. Men tokens pr. sekund akkumulerer: hvis hvert opkald genererer 500 tokens, er forskellen mellem 100 tok/s og 30 tok/s 5 sekunder vs. 17 sekunder pr. opkald. Over 50 opkald er det 4 minutter vs. 14 minutter for den samme opgave. Konteksthåndtering betyder også noget: agentsamtaler vokser, mens de arbejder, og udbydere, der bliver langsommere ved 32K+ tokens, vil flaskehalse dit workflow.
Når du kender din workload, kan du evaluere ordentligt. Men først skal du forstå, hvorfor disse afvejninger eksisterer.
Hvorfor disse afvejninger eksisterer
De fleste inferensudbydere kører på GPU'er, så afvejningerne nedenfor afspejler GPU-baseret infrastruktur. Alternative arkitekturer som Googles TPU'er eller SambaNovas dataflow-chips håndterer nogle af disse anderledes, men GPU'er forbliver industriens baseline.
Prefill vs. Decode: To forskellige problemer
Når du sender en anmodning til en LLM, sker der to forskellige faser:
Prefill (behandling af dit input): Modellen læser hele din prompt og finder ud af, hvordan hvert ord relaterer til hvert andet ord (dette kaldes "attention"). Den behandler alle input-tokens på én gang, parallelt. GPU'er excellerer i denne form for parallelt arbejde og kører med høj udnyttelse.
Decode (generering af output): Nu producerer modellen output-tokens én ad gangen. Vægtene ligger i GPU-hukommelsen, men for hver token skal GPU'en læse gennem dem for at beregne den næste forudsigelse. Flaskehalsen er hukommelsesbåndbredde, ikke beregning. GPU'er sidder inaktive og venter på, at data ankommer, hvilket reducerer udnyttelsen betydeligt.
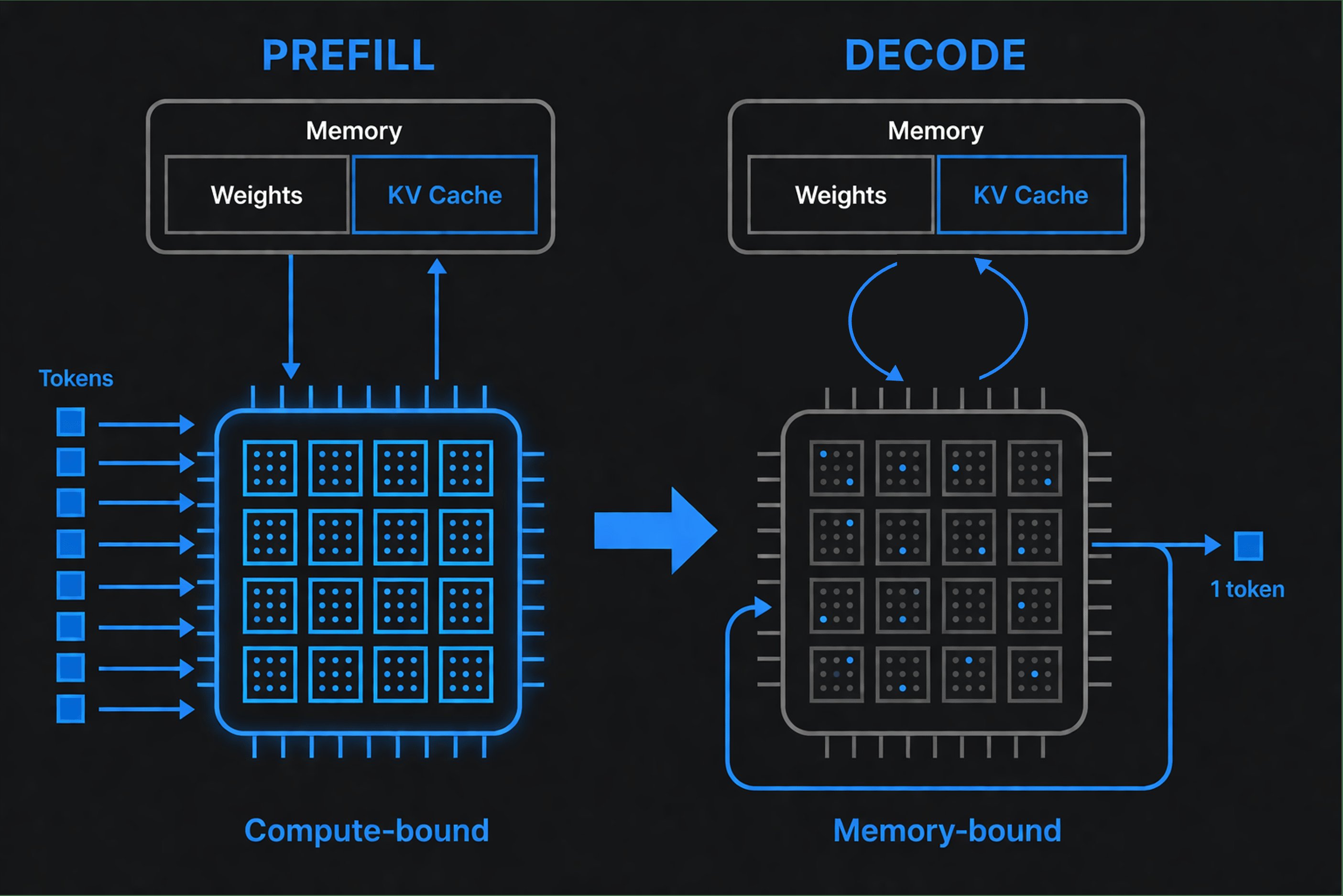
Dette skaber to separate målinger:
- Tid til første token (TTFT): Hvor længe før output starter. Bestemt af prefill.
- Tokens pr. sekund: Hvor hurtigt tokens streamer til dig derefter. Bestemt af decode.
En udbyder optimeret til prefill viser hurtig TTFT, men kan have langsom decode. En optimeret til decode streamer hurtigt, men tager længere tid om at starte. Ingen er "bedre". Det afhænger af din workload.
Kontekstlængde: Den skjulte omkostningsmultiplikator
De fleste udbydere opkræver den samme pris pr. token uanset kontekstlængde. Men beregningsomkostningerne er ikke flade.
Prefill skalerer kvadratisk i standard transformer-attention. Modellen beregner, hvordan hvert ord relaterer til hvert andet ord. En prompt på 1.000 tokens betyder 1 million relationsberegninger. En prompt på 10.000 tokens betyder 100 millioner. Fordobl din kontekst, attention-beregning firedobles omtrent. (Moderne optimeringer som FlashAttention reducerer dette i praksis, men skaleringspresset forbliver.)
Reelle tal fra Meta, der kører Llama 3 405B:
- 128K tokens: 3,8 sekunders prefill
- 1M tokens: 77 sekunders prefill
Decode bliver også langsommere med kontekst. Under generering gemmer modellen mellemberegninger i en "KV-cache" - en kladdeblok over samtalen hidtil. Denne cache vokser lineært med kontekst. En samtale på 128K kræver ~40 GB bare til cachen på en 70B-model.
For hver ny token læser modellen hele denne cache. Større cache = mere hukommelsesbåndbredde forbrugt = langsommere tokens pr. sekund. Og da hukommelse deles på tværs af brugere, betyder større caches færre samtidige brugere.
Hvordan håndterer udbydere dette? På tre måder:
- Krydssubsidiering: Brugere med kort kontekst betaler for brugere med lang kontekst
- Differentieret prissætning: Google opkræver 2x for kontekst over 200K tokens
- Forringet service: Throttle eller deprioritér anmodninger med lang kontekst
Hvis din workload er konteksttung, betyder dette noget. Hvis det er korte prompts, subsidierer du måske andre.
Batching: Hvordan udbydere bytter dine tokens/s for deres kapacitet
Hvad er batching? I stedet for at behandle én anmodning ad gangen, grupperer udbydere flere anmodninger og behandler dem samtidigt. Mere effektivt for GPU'en. Som en bus, der transporterer 50 mennesker i stedet for 50 taxier.
Ved batch size 1 har GPU'er lav udnyttelse, fordi de venter på hukommelse. Ved batch size 128 indlæser de modelvægtene én gang og behandler alle 128 anmodninger sammen. Udbyderen kan betjene langt flere brugere. Højere kapacitet.
Hagen: dine tokens pr. sekund falder. En model, der leverer 400 tok/s til en enkelt bruger, kan levere 30-50 tok/s pr. bruger, når den batches med 127 andre. Alle venter på alle. (Moderne systemer bruger continuous batching for at reducere denne afvejning, men det eliminerer den ikke.)
For batchbehandlings-workloadser dette fint. Du vil have, at udbyderen maksimerer kapaciteten; individuelle tokens pr. sekund betyder ikke noget.
For interaktive workloadser dette forfærdeligt. Din bruger er ligeglad med, at systemet behandlede 10.000 anmodninger det sekund. De bekymrer sig om, at deres svar tog 3 sekunder.
Når en udbyder citerer "anmodninger pr. sekund" eller "tokens pr. sekund", spørg: er det total systemkapacitet, eller tokens pr. sekund som hver bruger oplever? Det er meget forskellige tal.
Kvantisering: Den præcision, du ikke får at vide om
Hvad er kvantisering? AI-modeller gemmer viden som milliarder af tal ("vægte"). Disse kan gemmes på forskellige præcisionsniveauer, som at måle med millimeter vs. centimeter. Lavere præcision sparer hukommelse, men kan forringe outputkvaliteten.
| Præcision | Hukommelsesbesparelse | Kvalitetseffekt |
|---|---|---|
| FP16/BF16 | Baseline | Ingen (de fleste modeller trænes på dette) |
| FP8 | ~50% | Minimal (<1% nøjagtighedstab) |
| INT8 | ~50% | Mindre (99%+ nøjagtighed bevaret) |
| INT4 | ~75% | Betydelig på krævende opgaver |
FP8 og INT8 er næsten usynlige for de fleste workloads. INT4 er hvor problemer kan opstå: forskning viser op til 59% nøjagtighedstab på opgaver med lang kontekst og 69,8% forringelse på svær ræsonnering i værste tilfælde. Effekten varierer kraftigt efter opgave; mange virkelige applikationer ser meget mindre fald, men ræsonnering med lang kontekst er særligt følsom.
De fleste udbydere annoncerer ikke deres kvantiseringsniveau. Nogle justerer dynamisk præcision baseret på belastning: fuld præcision kl. 02, kvantiseret i spidsbelastningstimer. Samme pris, forskelligt produkt.
For batchbehandlingkan aggressiv kvantisering være acceptabel. Du optimerer omkostninger; små nøjagtighedsfald er tolerable.
For produktionsapplikationerskal du vide, hvilken præcision du får.
Hvorfor output-tokens koster mere
De fleste udbydere opkræver 4-6x mere for output-tokens end input:
| Udbyder | Input €/M | Output €/M | Forhold |
|---|---|---|---|
| OpenAI GPT-5.4 | €2.30 | €13.80 | 6x |
| Anthropic Claude Opus 4.6 | €4.60 | €23.00 | 5x |
| Google Gemini 3.1 Pro | €1.84 | €11.00 | 6x |
| DeepSeek V3.2 | €0.13 | €0.26 | 2x |
Source, konverteret til ~€0,92/$
Hvorfor? Husk forskellen mellem prefill og decode: inputbehandling holder GPU'en beskæftiget, outputgenerering gør ikke. Multiplikatoren afspejler groft forskelle i GPU-effektivitet mellem input- og outputbehandling.
Bemærk DeepSeek på 2x. DeepSeek kombinerer MoE (671B parametre, kun 37B aktive) med sparse attention, der reducerer beregning ved lang kontekst. V4, udgivet i april 2026, presser dette endnu længere. Arkitekturen ændrer økonomien.
Input-tunge workloads (RAG, lange prompts, korte svar) drager fordel af denne opdeling. Output-tunge workloads (kodegenerering, indholdsskabelse) rammes af 4-6x multiplikatoren.
Evaluering af udbydere til din workload
Bevæbnet med dette kan du stille de rigtige spørgsmål.
For interaktive / brugerfokuserede workloads:
"Hvad er jeres p50 og p99 TTFT ved min kontekstlængde?"
Benchmarks i tomgang er ligegyldige. Bed om tal under belastning.
Advarselstegn: De har kun syntetiske benchmarks.
"Hvad er jeres tokens pr. sekund pr. bruger?"
Tokens pr. sekund, der streamer til hver bruger, ikke total systemkapacitet.
Advarselstegn: De citerer "op til"-tal eller systemdækkende målinger.
For batchbehandling:
"Hvad er jeres maksimale vedvarende kapacitet?"
Totale tokens pr. time, du kan sende igennem.
Advarselstegn: De kan ikke adskille kapacitetsmålinger fra hastighed pr. bruger.
"Hvilken præcision serverer I ved højt volumen?"
INT4 ved skalering kan være fint til din use case.
Advarselstegn: De vil ikke oplyse kvantiseringsniveauer.
For agentic / long-context workloads:
"Hvad er jeres tokens pr. sekund ved 32K, 64K, 128K kontekst?"
Agentic workflows venter på komplette svar. Tokens pr. sekund ved lang kontekst er kritisk.
Advarselstegn: De citerer kun TTFT, eller har ingen kontekstlængde-opdeling.
"Hvordan forringes ydeevnen under samtidige anmodninger med lang kontekst?"
Lang kontekst forbruger hukommelse, der kunne betjene andre brugere. Hvad sker der ved skalering?
Advarselstegn: De ved ikke, hvad du spørger om.
For voice / realtid:
"Hvad er jeres end-to-end latens for tale-til-tekst → LLM → tekst-til-tale?"
Under 500ms, ellers er det ikke realtid.
Advarselstegn: De citerer kun LLM-latens, ikke fuld pipeline.
Hvorfor dette betyder noget nu
Æraen med fast pris, alt-hvad-du-kan-spise AI er ved at slutte.
GitHub flyttede for nylig Copilot til forbrugsbaseret fakturering. Anthropic strammer Claude-abonnementsgrænser, da agentic brug overstiger, hvad faste planer var bygget til. Disse ændringer på applikationsniveau afspejler virkeligheden nedenunder: inferens koster penge, og jo flere tokens du forbruger, jo mere koster det at betjene dig. Efterhånden som de subsidier, der finansierede ubegrænsede planer, forsvinder, bliver det vigtigere, ikke mindre vigtigt, at forstå, hvad du faktisk køber på inferenslaget.
Nogle udbydere gør nu dette eksplicit - Googles Flex vs. Priority-niveauer, Amazon Bedrocks differentierede prissætning - og anerkender, at hastighed i sig selv har værdi. Og disse afvejninger intensiveres med større modeller: modeller med billioner af parametre kan ikke være på en enkelt GPU og kræver kompleks parallelisering, hvilket gør højhastighedsinferens endnu sværere at levere.
De udbydere, der kun konkurrerer på pris, vil skære hjørner, du ikke kan se: kvantisering, batching, throttling. Dem, der konkurrerer på de målinger, der betyder noget for din workload, vil tage mere betalt og være det værd.
Stop med at sammenligne pris pr. million tokens. Start med de fem faktorer, og find de afvejninger, der passer til din workload.
Infercom udgiver realtidsbenchmarks på infercom.ai/performance, hvis du selv vil sammenligne disse målinger.
Skrevet af Thomas Vits, med assistance fra AI.
Kilder
Benchmarks og ydeevne
- DeepInfra: DeepSeek V3.2 API Benchmarks
- MLCommons MLPerf Inference v5.0
- Artificial Analysis LLM Leaderboard
Arkitektur og beregning
- Meta Engineering: Scaling LLM Inference
- Prefill Is Compute-Bound, Decode Is Memory-Bound
- NVIDIA: KV Cache Offloading
- Transformer FLOPs Analysis
Kvantisering
- Red Hat: vLLM FP8 Benchmarks
- Red Hat: Half Million Evaluations on Quantized LLMs
- EMNLP 2025: INT4 Long-Context Degradation
- COLM 2025: Quantization Impact on Reasoning