Insights
Tekniske dybdegående analyser, brancheindsigt og perspektiver på AI-inferens fra Infercom-teamet.
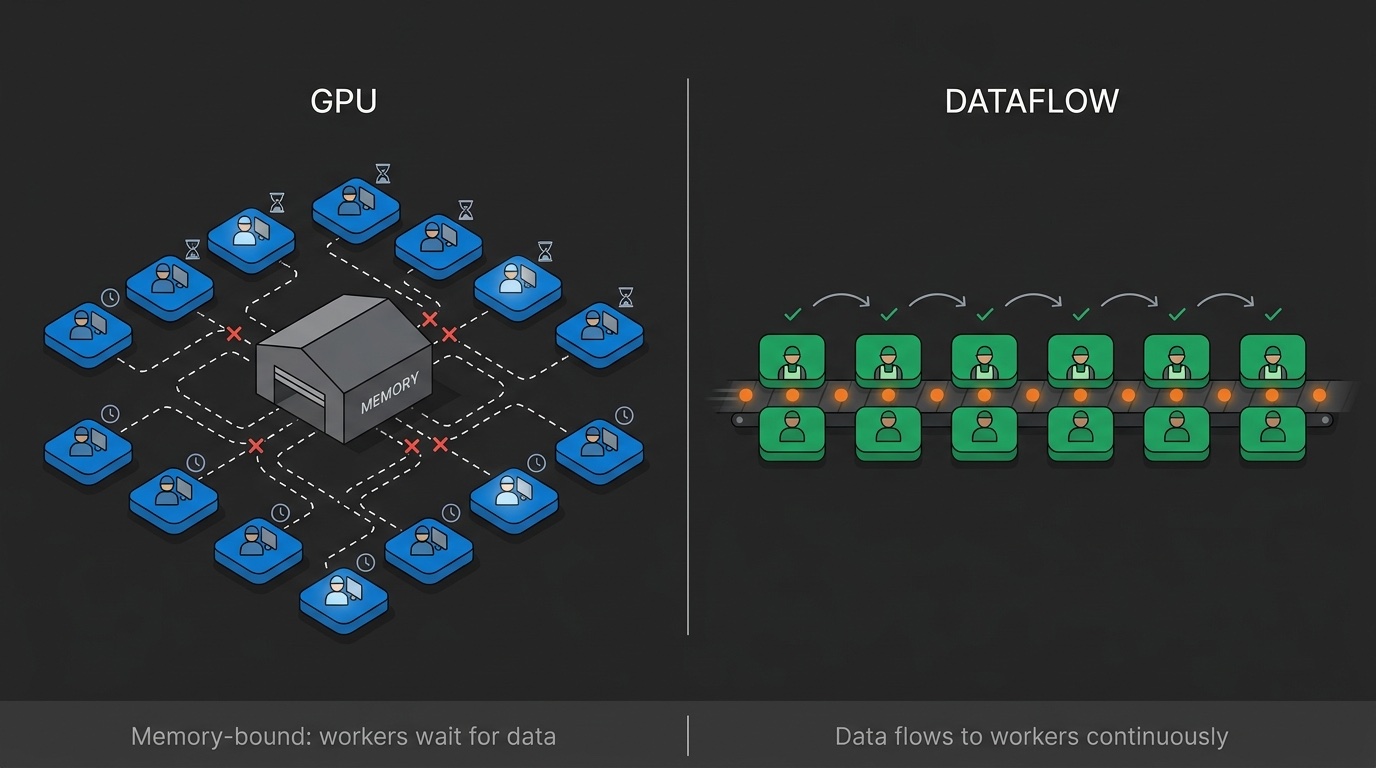
713 Tokens i Sekundet: Arkitekturen bag Ultraspeed
Hvorfor dataflow-arkitektur overgår GPU'er til LLM-inferens. Teknisk forklaring af hukommelses-flaskehalse, rumlig eksekvering og decode-problemet.
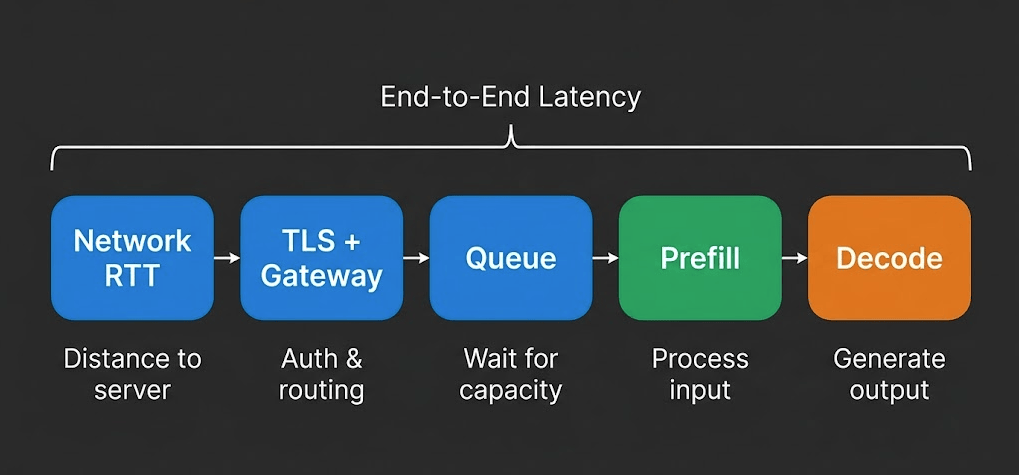
LLM Inference-hastighed forklaret: TTFT, gennemstrømning og hvad der virkelig betyder noget
Når én udbyder reklamerer med 400 tok/s og en anden hævder under 200ms latenstid, måler de forskellige ting. Lær hvilke metrikker der betyder noget for din workload.

Inferenshastighed i Agentic Coding: Hvorfor Token-gennemstrømning er vigtig
Agentic coding værktøjer forbruger 500K-2M tokens per udvikler om dagen. Denne artikel forklarer, hvorfor inferenshastighed er vigtig, og hvordan man konfigurerer værktøjer som Cursor, Cline og Codex CLI for højere gennemstrømning.
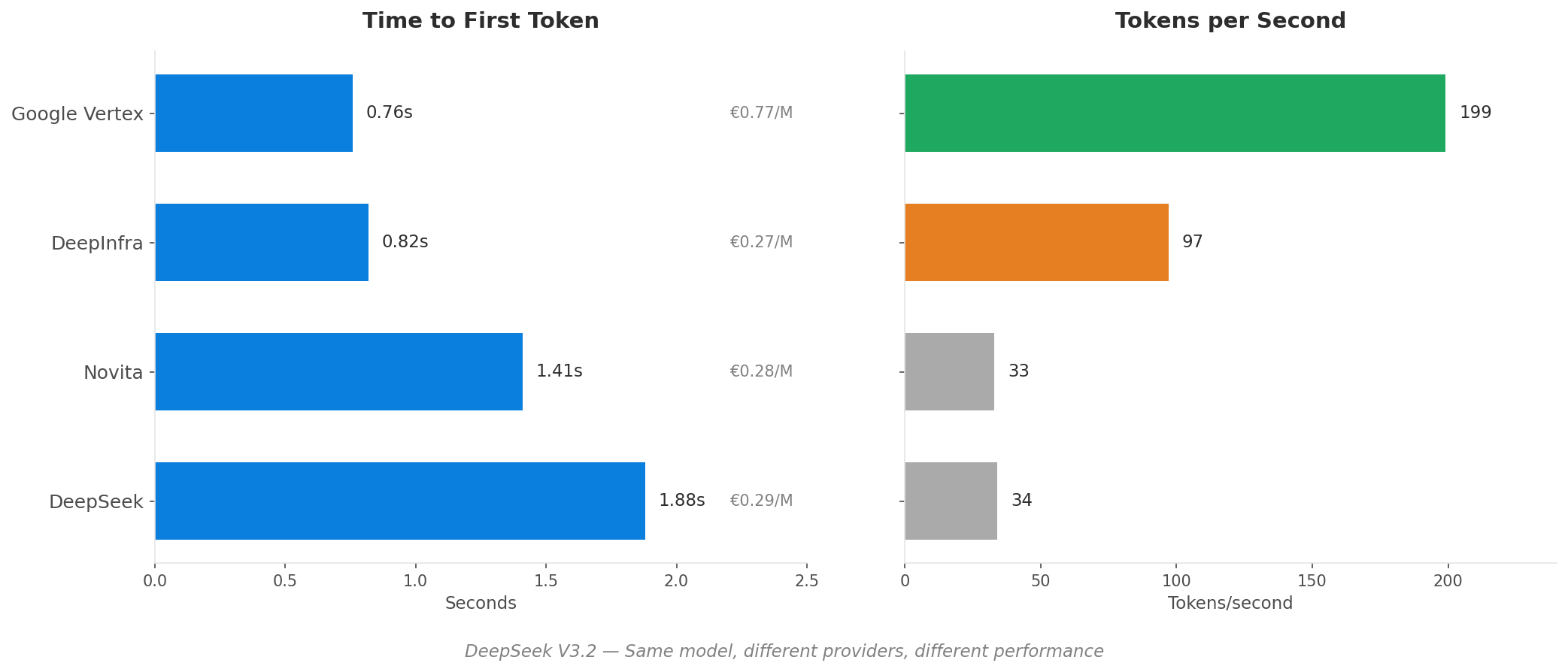
Hvad 'Pris per Token' ikke fortæller dig
Hvis du sammenligner AI-inferensudbydere kun efter tokenpris, overser du de faktorer, der faktisk bestemmer omkostninger og ydeevne.