Was in jeder Phase passiert
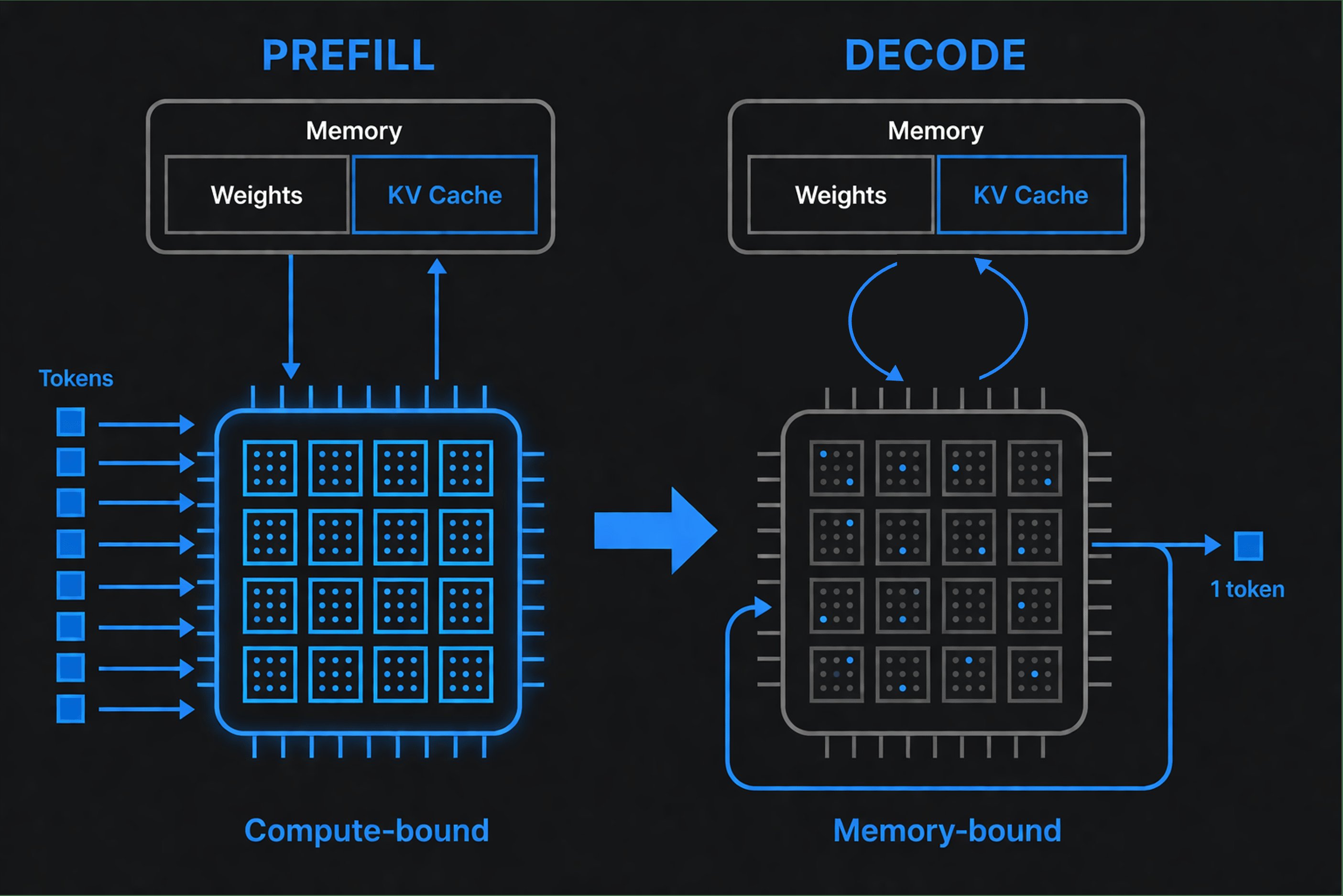
Während des Prefills liest das Modell den gesamten Prompt auf einmal - eine große, hochparallele Matrix-Matrix-Berechnung, die die Recheneinheiten der Hardware effektiv auslastet. Das Ergebnis ist der KV-Cache: die Attention-Keys und -Values für jedes Prompt-Token, einmal berechnet und für den Rest der Anfrage wiederverwendet. Der Prefill endet, wenn das erste Ausgabe-Token erzeugt wird - weshalb die Prompt-Länge die Zeit bis zum ersten Token bestimmt.
Während des Decodes generiert das Modell ein Token, hängt es an den Kontext an und wiederholt den Vorgang. Jeder Schritt ist eine schmale Matrix-Vektor-Operation, die den zwischengespeicherten Zustand wiederverwendet - aber für jedes einzelne Token die Modellgewichte aus dem Speicher streamen muss. Diese Phase ist speichergebunden: Die Geschwindigkeit, mit der Gewichte und Cache-Daten aus dem Speicher bewegt werden, dominiert die Latenz, nicht die Arithmetik.
Warum die Unterscheidung wichtig ist
Die beiden Phasen verlangen unterschiedliche Hardware. Der Prefill belohnt rohe Rechenleistung; der Decode belohnt Speicherbandbreite und effiziente Datenbewegung. Der Engineering-Leitfaden von Databricks bringt es praktisch auf den Punkt: Die Speicherbandbreite ist ein besserer Prädiktor für die Token-Generierungsgeschwindigkeit als die Spitzenrechenleistung. Ein Chip mit spektakulären FLOPS kann trotzdem langsam Token generieren, wenn er am Speicher hängt.
Das ist auch der Grund, warum GPU-basiertes Serving stark auf Batching setzt: Die Amortisierung jedes Gewichtsladens über viele gleichzeitige Anfragen stellt die Auslastung während des Decodes wieder her - auf Kosten der Geschwindigkeit pro Nutzer. Architekturen, die um Datenbewegung herum entworfen sind, wie die Dataflow-Hardware, die wir betreiben, greifen den Decode-Engpass stattdessen direkt an und halten die Auslastung auch bei kleinen Batch-Größen hoch.
Die Metriken durch diese Brille lesen
Die Prefill-Performance zeigt sich in der TTFT; die Decode-Performance zeigt sich in der Inter-Token-Latenz und den Ausgabe-Token pro Sekunde. Eine Einschränkung aus der Forschungsliteratur: Die Aufteilung rechengebunden/speichergebunden gilt für übliche Serving-Batch-Größen - bei sehr großen Batch-Größen kann der Decode in Richtung rechengebunden kippen. Der Branchentrend zum disaggregierten Serving - Prefill und Decode auf getrennten, spezialisierten Hardware-Pools - existiert genau deshalb, weil die beiden Phasen so unterschiedlich sind.
Quellen
Verwandte Begriffe
TTFT (Zeit bis zum ersten Token)
Wie lange ein Nutzer zwischen dem Absenden einer Anfrage und dem Erscheinen des ersten Tokens der Antwort wartet.
Inter-Token-Latenz (ITL)
Der durchschnittliche Zeitabstand zwischen aufeinanderfolgenden Token während der Generierung - auch TPOT genannt.
Dataflow-Architektur
Das Ausführungsmodell, bei dem Daten als Pipeline durch die Operationen strömen - und die Kernel-für-Kernel-Roundtrips der GPU-Ausführung entfallen.
Context Window
Die maximale Textmenge in Tokens, die ein Modell auf einmal berücksichtigt - Prompt plus Ausgabe. Die Länge prägt Geschwindigkeit und Kosten direkt.
Erfahren Sie, wie SambaNovas Dataflow-Architektur die Ökonomie der Inferenz verändert - und warum wir darauf aufbauen.