What happens in each phase
During prefill, the model reads the entire prompt at once - a large, highly parallel matrix-matrix computation that effectively saturates the hardware's compute units. The result is the KV cache: the attention keys and values for every prompt token, computed once and reused for the rest of the request. Prefill ends when the first output token is produced, which is why prompt length drives time to first token.
During decode, the model generates one token, appends it to the context, and repeats. Each step is a thin matrix-vector operation that reuses the cached state - but must stream the model weights from memory for every single token. This phase is memory-bound: the speed at which weights and cache data move from memory dominates the latency, not arithmetic.
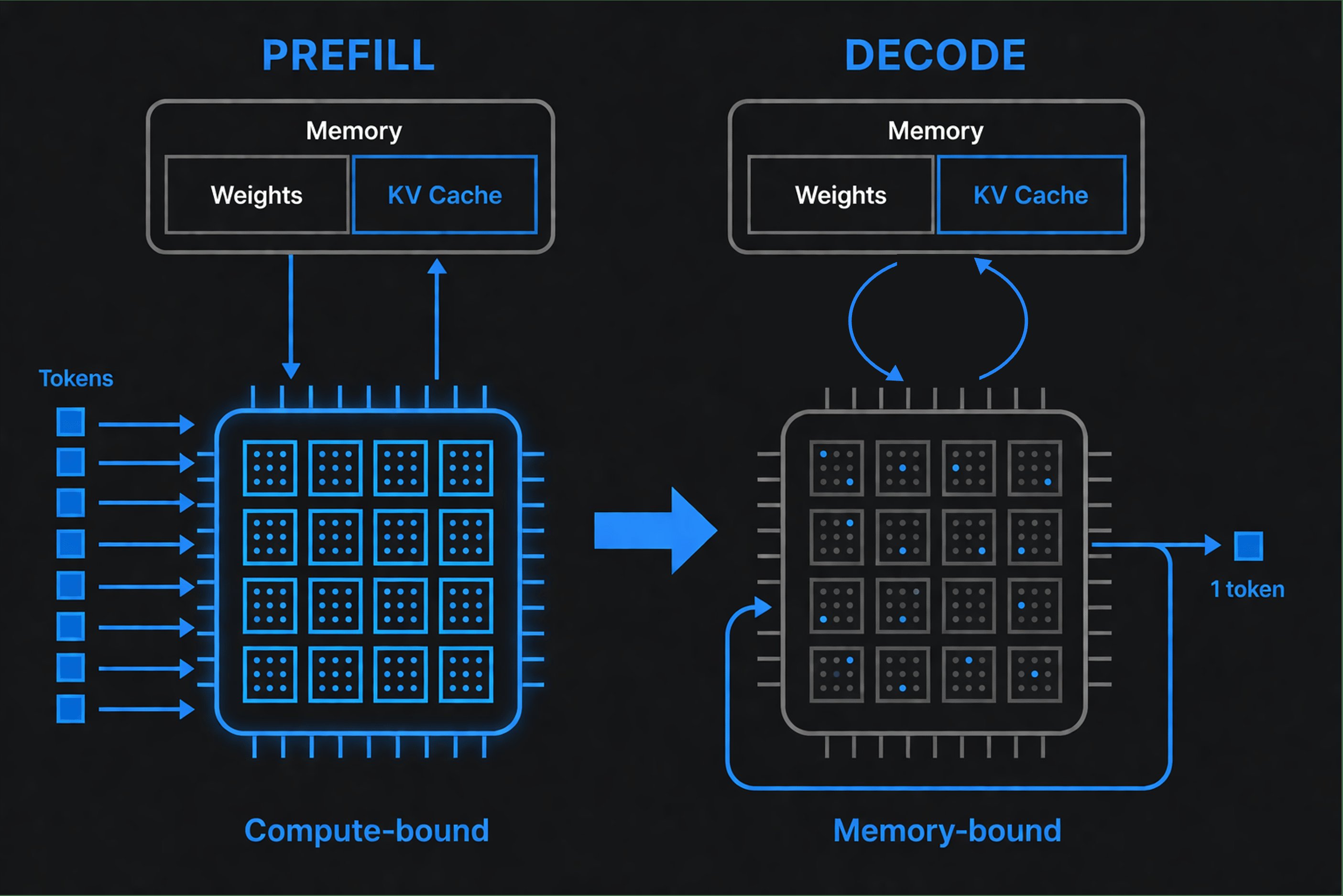
Why the distinction matters
The two phases want different hardware. Prefill rewards raw compute; decode rewards memory bandwidth and efficient data movement. Databricks' engineering guide makes the practical point: memory bandwidth is a better predictor of token generation speed than peak compute performance. A chip with spectacular FLOPS can still generate tokens slowly if it stalls on memory.
This is also why GPU-based serving leans heavily on batching: amortizing each weight load across many concurrent requests recovers utilization during decode - at the cost of per-user speed. Architectures designed around data movement, like the dataflow hardware we run, attack the decode bottleneck directly instead, keeping utilization high even at low batch sizes.
Reading the metrics through this lens
Prefill performance shows up as TTFT; decode performance shows up as inter-token latency and output tokens per second. One qualifier from the research literature: the compute-bound/memory-bound split holds at common serving batch sizes - at very large batch sizes decode can shift toward compute-bound. The industry trend of disaggregated serving - running prefill and decode on separate, specialized hardware pools - exists precisely because the two phases are so different.
Sources
Related terms
TTFT (Time to First Token)
How long a user waits between sending a request and seeing the first token of the response.
Inter-Token Latency (ITL)
The average time gap between consecutive tokens during generation - also called TPOT.
Dataflow Architecture
The execution model where data streams through operations as a pipeline - eliminating the kernel-by-kernel round trips of GPU execution.
Context Window
The maximum amount of text, in tokens, a model can consider at once - prompt plus output. Its length directly shapes inference speed and cost.
Learn how SambaNova's dataflow architecture changes the economics of inference - and why we built on it.