Hvad der sker i hver fase
Under prefill læser modellen hele prompten på én gang - en stor, stærkt parallel matrix-matrix-beregning, der reelt mætter hardwarens compute-enheder. Resultatet er KV-cachen: attention-keys og -values for hver prompt-token, beregnet én gang og genbrugt for resten af forespørgslen. Prefill slutter, når den første output-token produceres, hvilket er grunden til, at promptlængden driver time to first token.
Under decode genererer modellen én token, tilføjer den til konteksten og gentager. Hvert trin er en tynd matrix-vektor-operation, der genbruger den cachede tilstand - men skal streame modelvægtene fra hukommelsen for hver eneste token. Denne fase er memory-bound: hastigheden, hvormed vægte og cache-data flyttes fra hukommelsen, dominerer latensen, ikke aritmetikken.
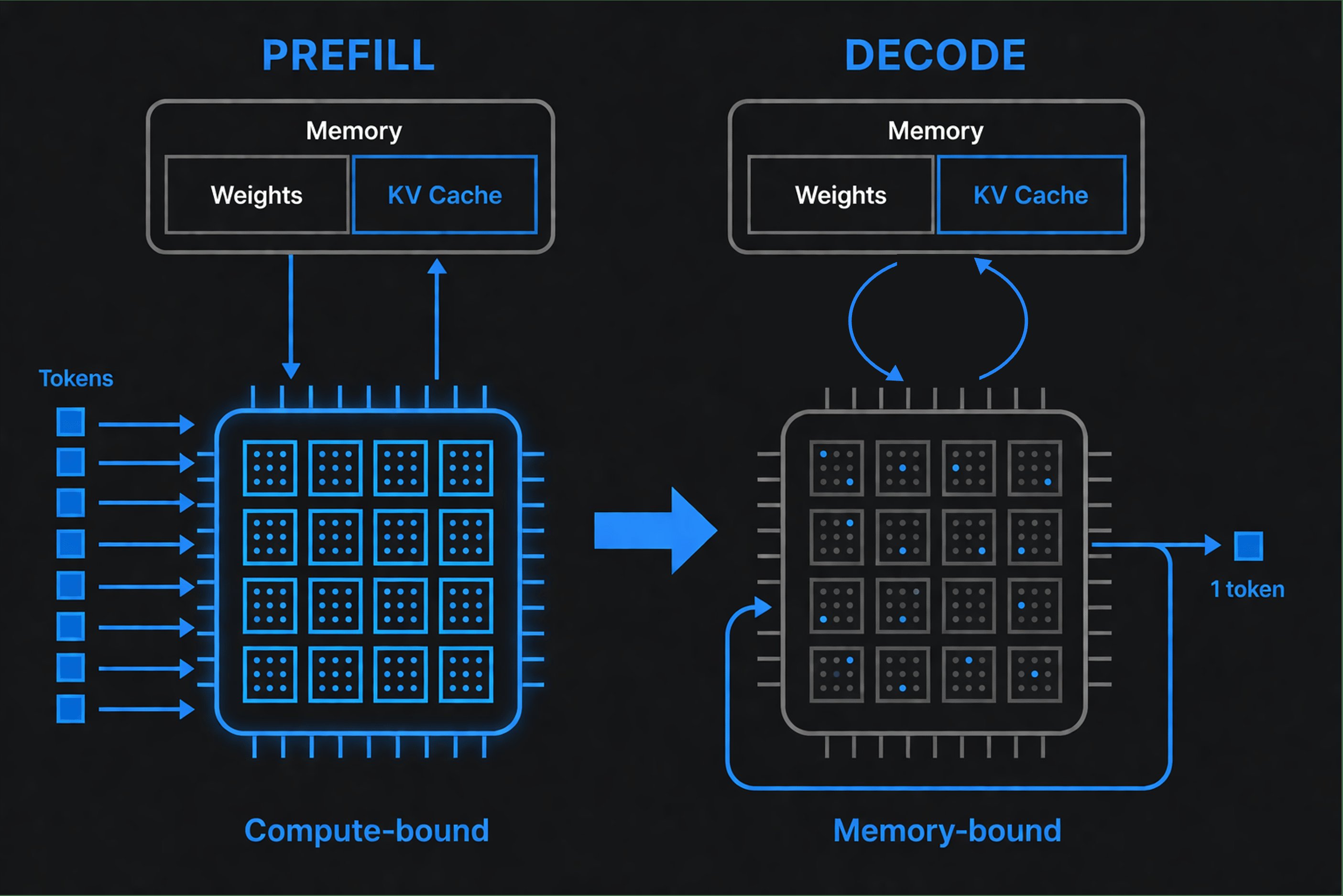
Hvorfor skelnen betyder noget
De to faser ønsker forskellig hardware. Prefill belønner rå compute; decode belønner hukommelsesbåndbredde og effektiv databevægelse. Databricks' engineering-guide gør den praktiske pointe klar: hukommelsesbåndbredde er en bedre prædiktor for token-genereringshastighed end peak compute-performance. En chip med spektakulære FLOPS kan stadig generere tokens langsomt, hvis den går i stå på hukommelsen.
Det er også derfor, GPU-baseret serving læner sig tungt op ad batching: at amortisere hver vægt-indlæsning over mange samtidige forespørgsler genvinder udnyttelsen under decode - på bekostning af per-bruger hastighed. Arkitekturer designet omkring databevægelse, som den dataflow-hardware vi kører, angriber i stedet decode-flaskehalsen direkte og holder udnyttelsen høj selv ved lave batch-størrelser.
At læse metrikkerne gennem denne linse
Prefill-performance viser sig som TTFT; decode-performance viser sig som inter-token latency og output tokens per sekund. Ét forbehold fra forskningslitteraturen: opdelingen i compute-bound/memory-bound holder ved almindelige serving-batch-størrelser - ved meget store batch-størrelser kan decode skifte mod compute-bound. Branchetendensen med disaggregeret serving - at køre prefill og decode på separate, specialiserede hardware-puljer - eksisterer netop, fordi de to faser er så forskellige.
Kilder
Relaterede begreber
TTFT (Time to First Token)
Hvor længe en bruger venter mellem at sende en forespørgsel og se den første token af svaret.
Inter-Token Latency (ITL)
Det gennemsnitlige tidsinterval mellem på hinanden følgende tokens under generering - også kaldet TPOT.
Dataflow-arkitektur
Eksekveringsmodellen hvor data streames gennem operationer som en pipeline - og eliminerer GPU-eksekveringens kernel-for-kernel-rundture.
Context Window
Den maksimale mængde tekst, i tokens, en model kan overveje på én gang - prompt plus output. Længden former direkte inference-hastighed og -omkostning.
Lær hvordan SambaNova's dataflow-arkitektur ændrer økonomien i inference - og hvorfor vi byggede på den.