Wenn Sie KI-gestützte Produkte entwickeln, brauchen Sie Inference: die Möglichkeit, einen Prompt an ein Modell zu senden und eine Antwort zu erhalten. Wenn Sie keine eigenen GPUs betreiben, kaufen Sie diese Leistung bei einem Anbieter.
Sobald Sie sich für ein Modell entschieden haben, gibt es oft mehrere Optionen, wo Sie es ausführen können. Open-Source-Modelle wie MiniMax, gpt-oss oder Mistral werden von Dutzenden konkurrierenden Anbietern bereitgestellt. Selbst proprietäre Modelle wie GPT oder Claude sind über mehrere Kanäle jenseits ihrer nativen APIs verfügbar.
Also filtern Sie nach den Grundlagen: DSGVO-Konformität, Datensouveränität, Zero-Data-Retention falls nötig. Dann vergleichen Sie die Preise. Anbieter A verlangt 0,27 € pro Million Tokens, Anbieter B verlangt 0,77 € für exakt dasselbe Modell. Einfache Wahl, oder?
Nicht ganz. Dasselbe Modell, buchstäblich identische Gewichte, kann bei verschiedenen Anbietern völlig unterschiedlich performen. Der Preis pro Token ist notwendig, aber selten ausreichend.
Was schiefgeht
Hier eine Geschichte, die ich schon mehrfach erlebt habe. Ein Team entwickelt ein KI-Feature und muss einen Anbieter wählen. Sie vergleichen Token-Preise, sehen dass einer 0,27 € pro Million Tokens verlangt und ein anderer 0,77 €, und wählen die günstigere Option. Es scheint eine offensichtliche Entscheidung zu sein.
Drei Monate später tauchen Probleme auf. Nutzer beschweren sich, dass die KI "langsam wirkt". Agentic Workflows, die in 2 Minuten fertig sein sollten, brauchen 15. Lange Dokumente verursachen Timeouts. Zu Stoßzeiten wird die Qualität unvorhersehbar.
Also wechseln sie den Anbieter, nachdem sie Monate an Integrationszeit verschwendet und Nutzer auf dem Weg frustriert haben.
Der Anbieter war nicht das Problem. Das Problem war, wie sie ihn bewertet haben.
Warum Preis pro Token irreführend ist
Schauen Sie sich echte Benchmark-Daten an. DeepSeek V3.2 bei vier Anbietern:
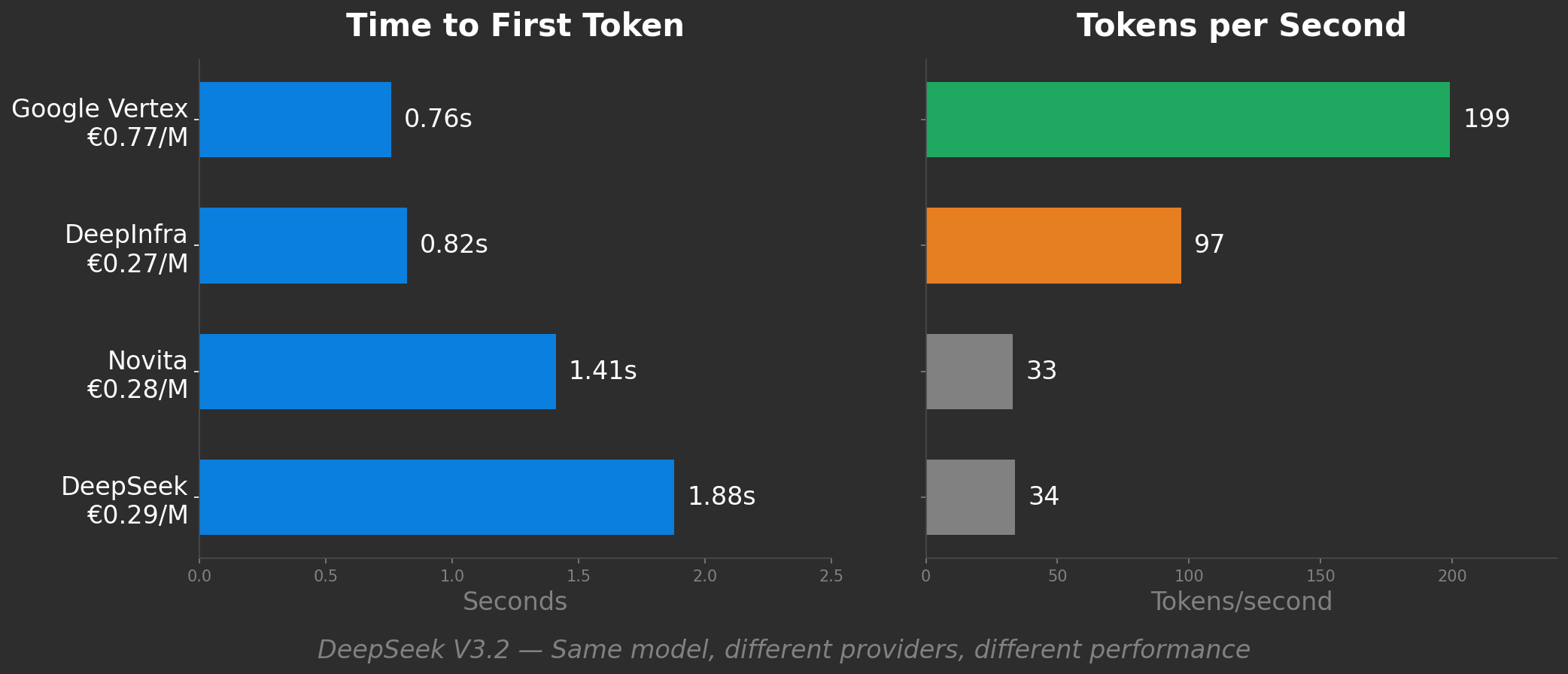
DeepInfra sieht wie die kluge Wahl aus: halb so schnell wie Google Vertex, aber ein Drittel des Preises. Novita und DeepSeek nativ sind ähnlich günstig, aber 6x langsamer als Vertex.
Aber "Preis pro Token" verrät Ihnen nichts davon. Es behandelt alle vier als gleichwertige Produkte. Das sind sie nicht.
Was wirklich zählt: Fünf Faktoren
Wenn Sie einen Prompt an eine Inference-API senden, übernimmt die Infrastruktur des Anbieters. Ihre Anfrage landet in einer Warteschlange, wird an Hardware geroutet, das Modell verarbeitet Ihre Eingabe, und Tokens beginnen zurückzustreamen. Fünf Dinge bestimmen, wie dieser Prozess performt und ob der Anbieter für Ihren Anwendungsfall funktioniert:
Time to First Token (TTFT): Wie lange, bis die Ausgabe erscheint? Nutzer müssen wissen, dass etwas passiert. Ein TTFT von 200ms fühlt sich reaktionsschnell an. Ein 2-sekündiger leerer Bildschirm fühlt sich kaputt an, selbst wenn die Gesamtantwortzeit am Ende gleich ist. Bedenken Sie, dass TTFT Netzwerklatenz einschließt: Ein EU-Nutzer, der einen US-Anbieter anfragt, addiert 100-150ms bevor Inference überhaupt startet. Und Durchschnitte lügen: Produktionssysteme scheitern an p95/p99-Latenz, nicht an Medianen.
Tokens pro Sekunde: Wie schnell streamen Tokens nach dem ersten? Das bestimmt, wann Sie die vollständige Antwort erhalten. Bei einer Chat-Oberfläche lesen Nutzer während des Streamings, daher ist Tokens pro Sekunde weniger wichtig. Bei einem agentischen Workflow, der auf die vollständige Antwort wartet, bevor der nächste Schritt beginnt, ist Tokens pro Sekunde alles. Auch hier zählt die Verteilung: Konstante 80 tok/s schlagen variable 50-150 tok/s.
Wenn Sie mit Web-Performance gearbeitet haben (Core Web Vitals, Lighthouse-Scores), kennen Sie den Unterschied: wann etwas erscheint vs. wann es nutzbar ist. TTFT entspricht First Contentful Paint. Tokens pro Sekunde entspricht Time to Interactive.
Kapazität: Kann der Anbieter Ihr Volumen bewältigen? Rate Limits, Concurrent Request Limits, ob die Leistung bei Skalierung nachlässt. Ein Anbieter kann bei Ihrem Proof-of-Concept schnell sein, Sie aber in der Produktion drosseln.
Kontextverarbeitung: Bleibt die Leistung bei langen Eingaben stabil? Ein 4K-Prompt und ein 64K-Prompt werden pro Token gleich bepreist, kosten den Anbieter aber sehr unterschiedlich viel zu bedienen. Manche Anbieter werden dramatisch langsamer. Andere drosseln. Andere berechnen mehr.
Qualität: Bekommen Sie volle Präzision, oder führt der Anbieter still eine komprimierte Version des Modells aus, um Speicher zu sparen? Niedrigere Präzision kann subtil schlechtere Ausgaben bedeuten, besonders bei schwierigem Reasoning oder Long-Context-Aufgaben.
Jeder Anbieter macht Trade-offs zwischen diesen fünf Faktoren plus Preis. Einen zu optimieren kostet oft einen anderen. Die Frage: Welche Trade-offs passen zu meiner Workload?
Verschiedene Workloads, verschiedene Prioritäten
Die richtigen Trade-offs hängen vollständig davon ab, was Sie bauen. Ein Chatbot und eine Batch-Processing-Pipeline haben entgegengesetzte Prioritäten. Für einen zu optimieren würde dem anderen schaden.
Eine grobe Orientierung, wie die fünf Faktoren typischerweise zusammenspielen. Ihr spezifischer Anwendungsfall kann abweichen (ein Chatbot mit sehr langen Gesprächen achtet mehr auf Kontextverarbeitung als ein typischer), aber dies gibt Ihnen einen Ausgangspunkt:
| Workload | TTFT | Tokens/s | Kapazität | Kontext | Qualität |
|---|---|---|---|---|---|
| Interaktiver Chat | ●●● | ● | ●● | ● | ●●● |
| Batch-Verarbeitung | ● | ● | ●●● | ● | ●● |
| Agentic Workflows | ● | ●●● | ●● | ●●● | ●●● |
| Voice AI / Echtzeit | ●●● | ●●● | ●● | ● | ●●● |
| RAG / Retrieval | ●● | ● | ● | ●●● | ●●● |
●●● = kritisch, ●● = relevant, ● = weniger wichtig
Beispiel: Agentic Workflows. Ein Agent, der 50 Inference-Aufrufe macht, um eine Aufgabe zu erledigen, kümmert sich wenig um TTFT. Kein Mensch schaut zwischen den Schritten zu. Aber Tokens pro Sekunde summiert sich: Wenn jeder Aufruf 500 Tokens generiert, ist der Unterschied zwischen 100 tok/s und 30 tok/s 5 Sekunden vs 17 Sekunden pro Aufruf. Über 50 Aufrufe sind das 4 Minuten vs 14 Minuten für dieselbe Aufgabe. Kontextverarbeitung zählt ebenfalls: Agent-Gespräche wachsen während der Arbeit, und Anbieter, die bei 32K+ Tokens langsamer werden, blockieren Ihren Workflow.
Sobald Sie Ihre Workload kennen, können Sie richtig evaluieren. Aber zuerst müssen Sie verstehen, warum diese Trade-offs existieren.
Warum diese Trade-offs existieren
Die meisten Inference-Anbieter laufen auf GPUs, daher spiegeln die folgenden Trade-offs GPU-basierte Infrastruktur wider. Alternative Architekturen wie Googles TPUs oder SambaNova's Dataflow-Chips handhaben einiges davon anders, aber GPUs bleiben der Industriestandard.
Prefill vs Decode: Zwei verschiedene Probleme
Wenn Sie eine Anfrage an ein LLM senden, passieren zwei unterschiedliche Phasen:
Prefill (Verarbeitung Ihrer Eingabe): Das Modell liest Ihren gesamten Prompt und ermittelt, wie jedes Wort zu jedem anderen Wort in Beziehung steht (das nennt man "Attention"). Es verarbeitet alle Input-Tokens gleichzeitig, parallel. GPUs sind hervorragend bei dieser Art paralleler Arbeit und laufen mit hoher Auslastung.
Decode (Generierung der Ausgabe): Jetzt produziert das Modell Output-Tokens einen nach dem anderen. Die Gewichte liegen im GPU-Speicher, aber für jedes Token muss die GPU sie durchlesen, um die nächste Vorhersage zu berechnen. Der Engpass ist Speicherbandbreite, nicht Rechenleistung. GPUs warten untätig auf Daten und fallen auf deutlich niedrigere Auslastung.
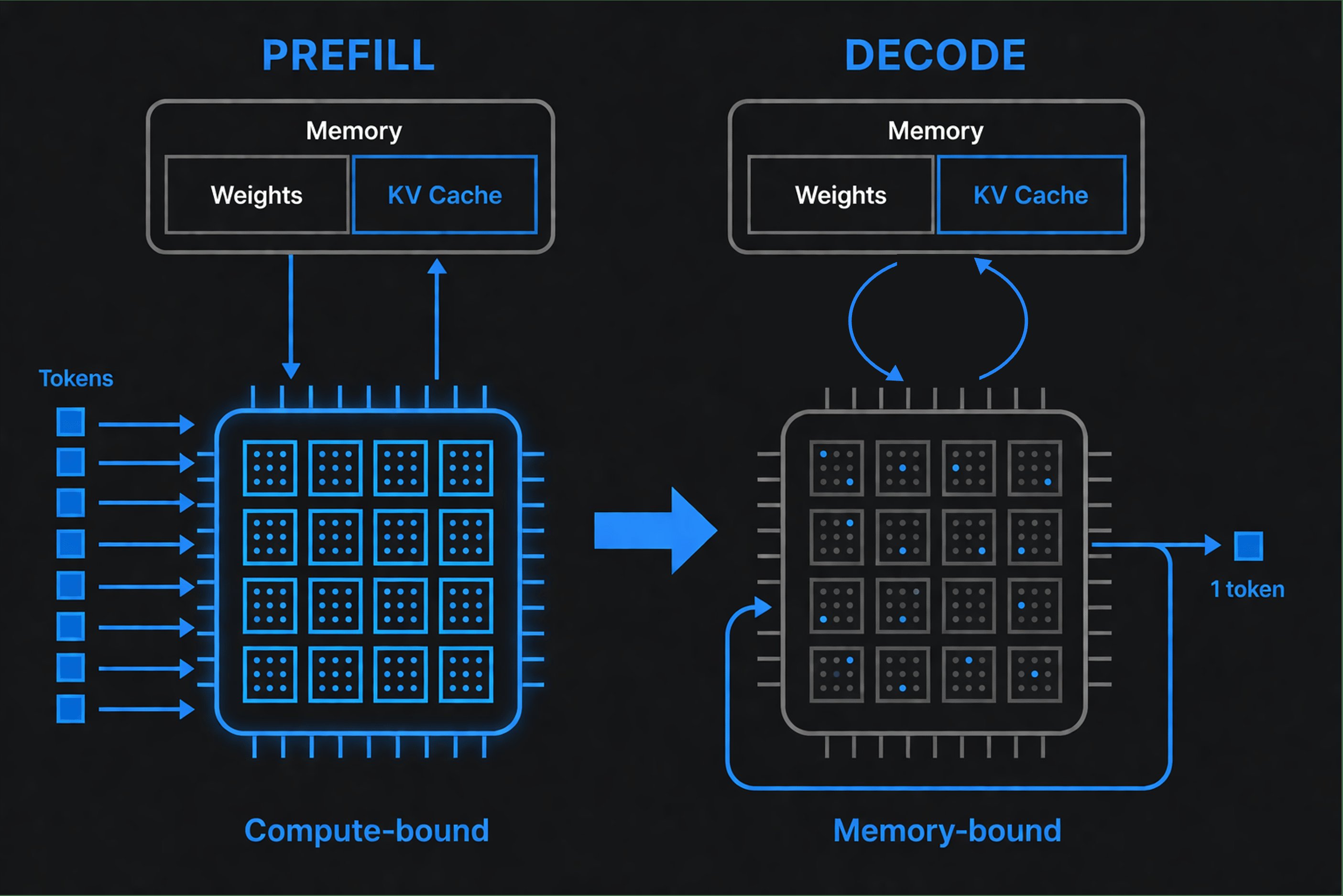
Das erzeugt zwei separate Metriken:
- Time to First Token (TTFT): Wie lange bis die Ausgabe startet. Bestimmt durch Prefill.
- Tokens pro Sekunde: Wie schnell Tokens danach zu Ihnen streamen. Bestimmt durch Decode.
Ein Anbieter, der für Prefill optimiert ist, zeigt schnelles TTFT, hat aber möglicherweise langsames Decode. Einer, der für Decode optimiert ist, streamt schnell, braucht aber länger zum Starten. Keines ist "besser". Es hängt von Ihrer Workload ab.
Kontextlänge: Der versteckte Kostenmultiplikator
Die meisten Anbieter berechnen denselben Token-Preis unabhängig von der Kontextlänge. Aber die Rechenkosten sind nicht konstant.
Prefill skaliert quadratisch bei Standard-Transformer-Attention. Das Modell berechnet, wie jedes Wort zu jedem anderen Wort in Beziehung steht. Ein 1.000-Token-Prompt bedeutet 1 Million Beziehungsberechnungen. Ein 10.000-Token-Prompt bedeutet 100 Millionen. Verdoppeln Sie Ihren Kontext, vervierfacht sich die Attention-Berechnung ungefähr. (Moderne Optimierungen wie FlashAttention reduzieren dies in der Praxis, aber der Skalierungsdruck bleibt.)
Echte Zahlen von Meta beim Betrieb von Llama 3 405B:
- 128K Tokens: 3,8 Sekunden Prefill
- 1M Tokens: 77 Sekunden Prefill
Decode wird ebenfalls langsamer mit Kontext. Während der Generierung speichert das Modell Zwischenberechnungen in einem "KV Cache", einem Notizblock der bisherigen Konversation. Dieser Cache wächst linear mit dem Kontext. Eine 128K-Konversation braucht ~40 GB allein für den Cache bei einem 70B-Modell.
Für jedes neue Token liest das Modell diesen gesamten Cache. Größerer Cache = mehr Speicherbandbreite verbraucht = langsamere Tokens pro Sekunde. Und da Speicher unter Nutzern geteilt wird, bedeuten größere Caches weniger gleichzeitige Nutzer.
Wie gehen Anbieter damit um? Auf drei Arten:
- Quersubventionierung: Short-Context-Nutzer zahlen für Long-Context-Nutzer
- Gestaffelte Preise: Google berechnet 2x für Kontext über 200K Tokens
- Service-Degradierung: Long-Context-Anfragen drosseln oder herabstufen
Wenn Ihre Workload kontextlastig ist, ist das wichtig. Bei kurzen Prompts subventionieren Sie möglicherweise andere.
Batching: Wie Anbieter Ihre Tokens/s gegen ihre Kapazität tauschen
Was ist Batching? Statt eine Anfrage nach der anderen zu verarbeiten, gruppieren Anbieter mehrere Anfragen und verarbeiten sie gleichzeitig. Effizienter für die GPU. Wie ein Bus, der 50 Leute transportiert statt 50 Taxis.
Bei Batch-Größe 1 haben GPUs niedrige Auslastung, weil sie auf Speicher warten. Bei Batch-Größe 128 laden sie Modellgewichte einmal und verarbeiten alle 128 Anfragen zusammen. Der Anbieter kann viel mehr Nutzer bedienen. Höhere Kapazität.
Der Haken: Ihre Tokens pro Sekunde sinkt. Ein Modell, das einem einzelnen Nutzer 400 tok/s liefert, liefert vielleicht 30-50 tok/s pro Nutzer im Batch mit 127 anderen. Alle warten auf alle. (Moderne Systeme nutzen Continuous Batching, um diesen Trade-off zu reduzieren, aber es eliminiert ihn nicht.)
Für Batch-Processing-Workloadsist das in Ordnung. Sie wollen, dass der Anbieter die Kapazität maximiert; individuelle Tokens pro Sekunde spielen keine Rolle.
Für interaktive Workloadsist das furchtbar. Ihren Nutzer interessiert nicht, dass das System in dieser Sekunde 10.000 Anfragen verarbeitet hat. Ihn interessiert, dass seine Antwort 3 Sekunden gedauert hat.
Wenn ein Anbieter "Anfragen pro Sekunde" oder "Tokens pro Sekunde" zitiert, fragen Sie: Ist das Gesamtsystemkapazität oder die Tokens pro Sekunde, die jeder Nutzer erlebt? Das sind sehr unterschiedliche Zahlen.
Quantisierung: Die Präzision, von der man Ihnen nicht erzählt
Was ist Quantisierung? KI-Modelle speichern Wissen als Milliarden von Zahlen ("Gewichte"). Diese können mit verschiedenen Präzisionsstufen gespeichert werden, wie Messen mit Millimetern vs. Zentimetern. Niedrigere Präzision spart Speicher, kann aber die Ausgabequalität verschlechtern.
| Präzision | Speicherersparnis | Qualitätsauswirkung |
|---|---|---|
| FP16/BF16 | Baseline | Keine (die meisten Modelle trainieren damit) |
| FP8 | ~50% | Minimal (<1% Genauigkeitsverlust) |
| INT8 | ~50% | Gering (99%+ Genauigkeit erhalten) |
| INT4 | ~75% | Signifikant bei anspruchsvollen Aufgaben |
FP8 und INT8 sind für die meisten Workloads nahezu unsichtbar. Bei INT4 können Probleme entstehen: Forschung zeigt bis zu 59% Genauigkeitsverlust bei Long-Context-Aufgaben und 69,8% Degradierung bei schwierigem Reasoning in Worst Cases. Die Auswirkung variiert stark nach Aufgabe; viele reale Anwendungen sehen viel kleinere Einbußen, aber Long-Context-Reasoning ist besonders empfindlich.
Die meisten Anbieter bewerben ihr Quantisierungsniveau nicht. Einige passen die Präzision dynamisch je nach Last an: volle Präzision um 2 Uhr nachts, quantisiert zu Stoßzeiten. Gleicher Preis, anderes Produkt.
Für Batch-Processingkann aggressive Quantisierung akzeptabel sein. Sie optimieren Kosten; kleine Genauigkeitseinbußen sind tolerierbar.
Für Produktionsanwendungenmüssen Sie wissen, welche Präzision Sie bekommen.
Warum Output-Tokens mehr kosten
Die meisten Anbieter berechnen 4-6x mehr für Output-Tokens als für Input:
| Anbieter | Input €/M | Output €/M | Verhältnis |
|---|---|---|---|
| OpenAI GPT-5.4 | €2.30 | €13.80 | 6x |
| Anthropic Claude Opus 4.6 | €4.60 | €23.00 | 5x |
| Google Gemini 3.1 Pro | €1.84 | €11.00 | 6x |
| DeepSeek V3.2 | €0.13 | €0.26 | 2x |
Source, umgerechnet bei ~0,92 €/$
Warum? Erinnern Sie sich an den Unterschied zwischen Prefill und Decode: Input-Verarbeitung hält die GPU beschäftigt, Output-Generierung nicht. Der Multiplikator spiegelt ungefähr die Unterschiede in der GPU-Effizienz zwischen Input- und Output-Verarbeitung wider.
Beachten Sie DeepSeek mit 2x. DeepSeek kombiniert MoE (671B Parameter, nur 37B aktiv) mit Sparse Attention, die Long-Context-Berechnung reduziert. V4, veröffentlicht im April 2026, treibt dies noch weiter. Die Architektur verändert die Wirtschaftlichkeit.
Input-lastige Workloads (RAG, lange Prompts, kurze Antworten) profitieren von dieser Aufteilung. Output-lastige Workloads (Code-Generierung, Content-Erstellung) werden vom 4-6x-Multiplikator getroffen.
Anbieter für Ihre Workload evaluieren
Mit diesem Wissen können Sie die richtigen Fragen stellen.
Für interaktive / nutzerorientierte Workloads:
"Was ist Ihr p50- und p99-TTFT bei meiner Kontextlänge?"
Idle-Benchmarks zählen nicht. Fragen Sie nach Zahlen unter Last.
Warnsignal: Sie haben nur synthetische Benchmarks.
"Was ist Ihre Tokens pro Sekunde pro Nutzer?"
Tokens pro Sekunde, die zu jedem Nutzer streamen, nicht Gesamtsystemkapazität.
Warnsignal: Sie zitieren "bis zu"-Zahlen oder systemweite Metriken.
Für Batch-Processing:
"Was ist Ihre maximale Dauerkapazität?"
Gesamte Tokens pro Stunde, die Sie durchschieben können.
Warnsignal: Sie können Kapazitätsmetriken nicht von Pro-Nutzer-Geschwindigkeit trennen.
"Mit welcher Präzision arbeiten Sie bei hohem Volumen?"
INT4 bei Skalierung kann für Ihren Anwendungsfall in Ordnung sein.
Warnsignal: Sie wollen Quantisierungsstufen nicht offenlegen.
Für Agentic / Long-Context Workloads:
"Was ist Ihre Tokens pro Sekunde bei 32K, 64K, 128K Kontext?"
Agentic Workflows warten auf vollständige Antworten. Tokens pro Sekunde bei langem Kontext ist kritisch.
Warnsignal: Sie zitieren nur TTFT oder haben keine Kontextlängen-Aufschlüsselung.
"Wie degradiert die Leistung bei gleichzeitigen Long-Context-Anfragen?"
Langer Kontext verbraucht Speicher, der anderen Nutzern dienen könnte. Was passiert bei Skalierung?
Warnsignal: Sie wissen nicht, wonach Sie fragen.
Für Voice / Echtzeit:
"Was ist Ihre End-to-End-Latenz für Speech-to-Text → LLM → Text-to-Speech?"
Unter 500ms oder es ist nicht Echtzeit.
Warnsignal: Sie zitieren nur LLM-Latenz, nicht die volle Pipeline.
Warum das jetzt wichtig ist
Die Ära der Flatrate-KI mit All-you-can-eat geht zu Ende.
GitHub hat kürzlich Copilot auf nutzungsbasierte Abrechnung umgestellt. Anthropic verschärft Claude-Abo-Limits, da Agentic-Nutzung das übersteigt, wofür Flatrate-Pläne konzipiert wurden. Diese Änderungen auf Anwendungsebene spiegeln die Realität darunter wider: Inference kostet Geld, und je mehr Tokens Sie verbrauchen, desto mehr kostet es, Sie zu bedienen. Da die Subventionen, die Unlimited-Pläne finanzierten, schwinden, wird es wichtiger - nicht weniger wichtig - zu verstehen, was Sie auf der Inference-Ebene tatsächlich kaufen.
Einige Anbieter machen dies jetzt explizit - Googles Flex- vs. Priority-Tiers, Amazon Bedrocks gestaffelte Preise - und erkennen an, dass Geschwindigkeit selbst einen Wert hat. Und diese Trade-offs verschärfen sich mit größeren Modellen: Billionen-Parameter-Modelle passen nicht auf eine einzelne GPU und erfordern komplexe Parallelisierung, was High-Speed-Inference noch schwieriger zu liefern macht.
Die Anbieter, die nur über den Preis konkurrieren, werden unsichtbar Abstriche machen: Quantisierung, Batching, Drosselung. Diejenigen, die bei den Metriken konkurrieren, die für Ihre Workload zählen, werden mehr verlangen und es wert sein.
Hören Sie auf, Preis pro Million Tokens zu vergleichen. Beginnen Sie mit den fünf Faktoren und finden Sie die Trade-offs, die zu Ihrer Workload passen.
Infercom veröffentlicht Echtzeit-Benchmarks unter infercom.ai/performance, wenn Sie diese Metriken selbst vergleichen möchten.
Geschrieben von Thomas Vits, mit Unterstützung von KI.
Quellen
Benchmarks & Leistung
- DeepInfra: DeepSeek V3.2 API Benchmarks
- MLCommons MLPerf Inference v5.0
- Artificial Analysis LLM Leaderboard
Architektur & Compute
- Meta Engineering: Scaling LLM Inference
- Prefill Is Compute-Bound, Decode Is Memory-Bound
- NVIDIA: KV Cache Offloading
- Transformer FLOPs Analysis
Quantisierung
- Red Hat: vLLM FP8 Benchmarks
- Red Hat: Half Million Evaluations on Quantized LLMs
- EMNLP 2025: INT4 Long-Context Degradation
- COLM 2025: Quantization Impact on Reasoning