Insights
Technische Deep Dives, Branchenanalysen und Perspektiven zu KI-Inferenz vom Infercom-Team.
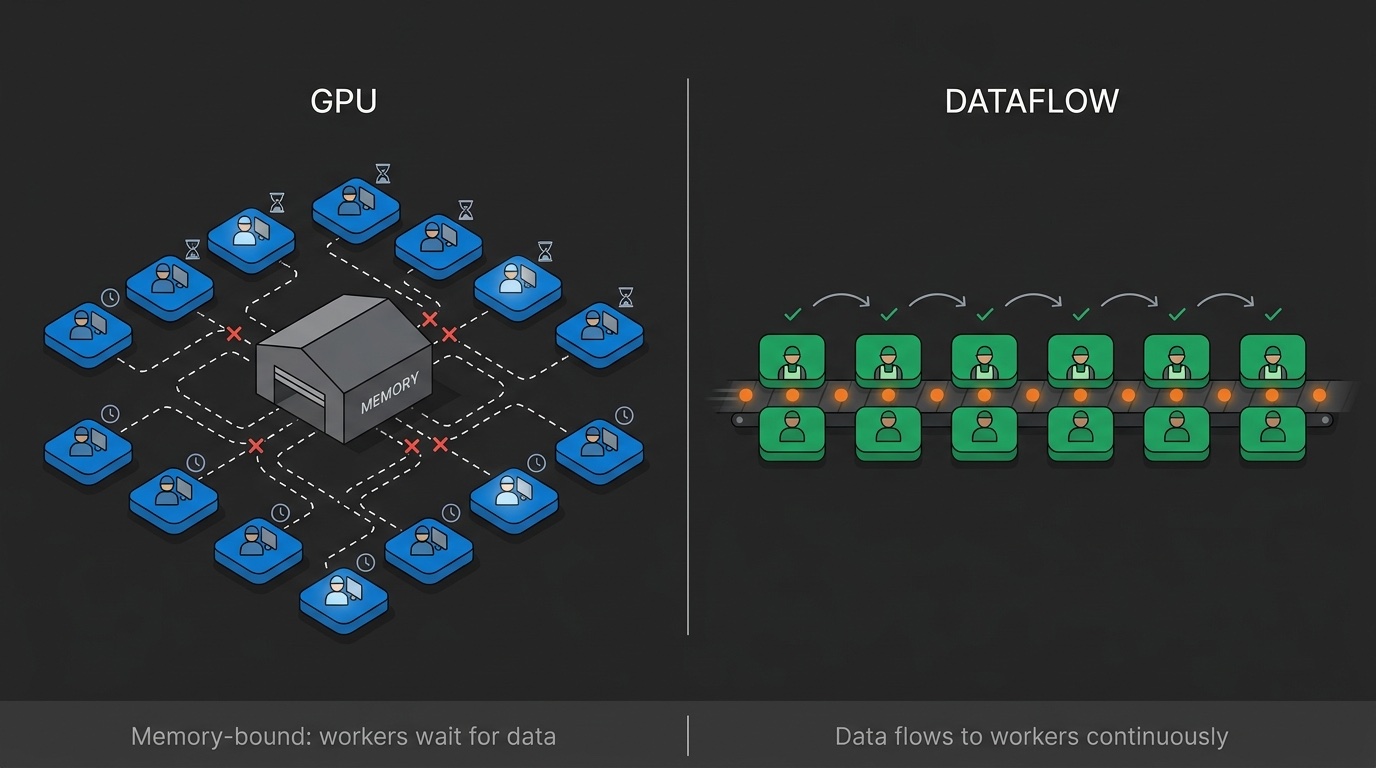
713 Tokens pro Sekunde: Die Architektur hinter Ultraspeed
Warum Dataflow-Architektur GPUs bei der LLM-Inferenz übertrifft. Technische Erklärung von Speicherengpässen, räumlicher Ausführung und dem Decode-Problem.
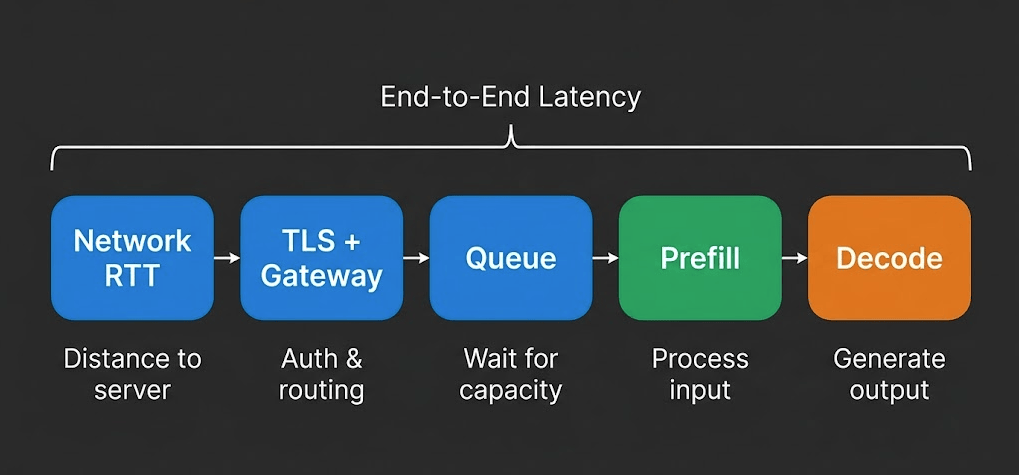
LLM Inference-Geschwindigkeit erklärt: TTFT, Durchsatz und was wirklich zählt
Wenn ein Anbieter mit 400 tok/s wirbt und ein anderer unter 200ms Latenz verspricht, messen sie verschiedene Dinge. Erfahren Sie, welche Metriken für Ihren Workload wichtig sind.

Inference-Geschwindigkeit beim Agentic Coding: Warum Token-Durchsatz wichtig ist
Agentic Coding Tools verbrauchen 500K-2M Token pro Entwickler pro Tag. Dieser Artikel erklärt, warum Inference-Geschwindigkeit wichtig ist und wie man Tools wie Cursor, Cline und Codex CLI für höheren Durchsatz konfiguriert.
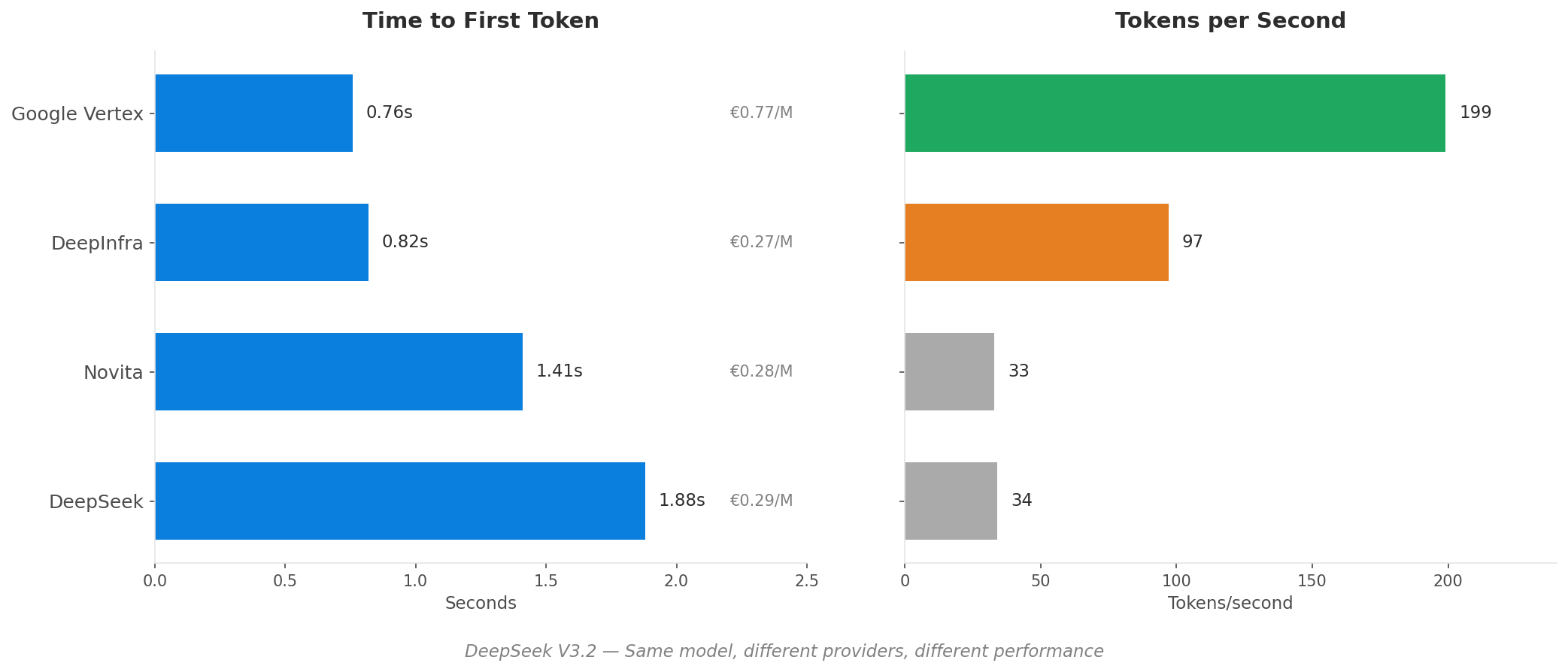
Was 'Preis pro Token' Ihnen nicht verrät
Wenn Sie KI-Inferenz-Anbieter nur nach dem Token-Preis vergleichen, übersehen Sie die Faktoren, die Kosten und Leistung tatsächlich bestimmen.