Se stai costruendo prodotti basati sull'AI, hai bisogno dell'inferenza: la capacità di inviare un prompt a un modello e ottenere una risposta. A meno che tu non gestisca le tue GPU, stai acquistando questo servizio da un provider.
Una volta scelto un modello, spesso hai diverse opzioni su dove eseguirlo. I modelli open-source come MiniMax, gpt-oss o Mistral sono serviti da decine di provider concorrenti. Anche i modelli proprietari come GPT o Claude sono disponibili attraverso molteplici canali oltre alle loro API native.
Quindi filtri per le basi: conformità GDPR, sovranità dei dati, zero-data-retention se ne hai bisogno. Poi confronti i prezzi. Il Provider A addebita €0,27 per milione di token, il Provider B addebita €0,77 per lo stesso identico modello. Scelta facile, giusto?
Non proprio. Lo stesso modello, letteralmente gli stessi pesi, servito da provider diversi può funzionare in modo completamente diverso. Il prezzo per token è necessario, ma raramente sufficiente.
Cosa va storto
Ecco una storia che ho visto ripetersi più volte. Un team sta costruendo una funzionalità AI e deve scegliere un provider. Confrontano i prezzi dei token, vedono che uno addebita €0,27 per milione di token e un altro €0,77, e scelgono l'opzione più economica. Sembra una decisione ovvia.
Tre mesi dopo, emergono i problemi. Gli utenti iniziano a lamentarsi che l'AI "sembra lenta". Gli agentic workflow che dovrebbero completarsi in 2 minuti ne impiegano 15. I documenti lunghi causano timeout. Durante le ore di punta, la qualità diventa imprevedibile.
Quindi cambiano provider, avendo sprecato mesi di tempo di integrazione e lasciato gli utenti frustrati lungo il percorso.
Il provider non era il problema. Il problema era come l'hanno valutato.
Perché il prezzo per token è fuorviante
Guarda i dati reali dei benchmark. DeepSeek V3.2 su quattro provider:
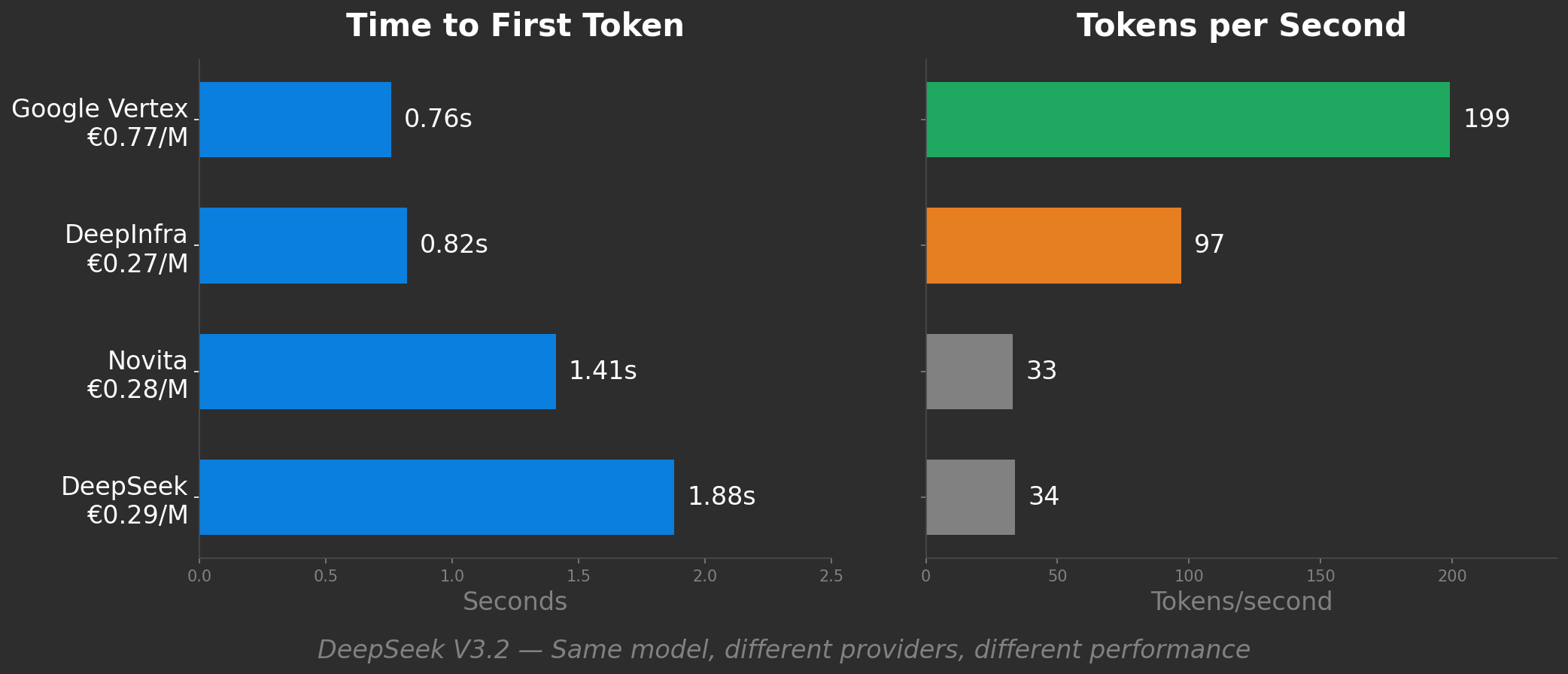
DeepInfra sembra la scelta intelligente: metà della velocità di Google Vertex, ma un terzo del prezzo. Novita e DeepSeek nativo sono similmente economici ma 6 volte più lenti di Vertex.
Ma il "prezzo per token" non ti dice nulla di tutto questo. Tratta tutti e quattro come prodotti equivalenti. Non lo sono.
Cosa conta davvero: cinque fattori
Quando invii un prompt a un'API di inferenza, l'infrastruttura del provider prende il controllo. La tua richiesta entra in una coda, viene instradata verso l'hardware, il modello elabora il tuo input e i token iniziano a tornare in streaming. Cinque cose determinano come si comporta quel processo e se il provider funziona per il tuo caso d'uso:
Time to First Token (TTFT): Quanto tempo prima che l'output inizi ad apparire? Gli utenti hanno bisogno di sapere che sta succedendo qualcosa. Un TTFT di 200ms sembra reattivo. Uno schermo vuoto per 2 secondi sembra rotto, anche se il tempo di risposta totale finisce per essere lo stesso. Ricorda che il TTFT include la latenza di rete: un utente EU che contatta un provider US aggiunge 100-150ms prima ancora che l'inferenza inizi. E le medie mentono: i sistemi di produzione si rompono sulla latenza p95/p99, non sulle mediane.
Token al secondo: Quanto velocemente i token arrivano in streaming dopo il primo? Questo determina quando ottieni la risposta completa. Per una UI di chat, gli utenti leggono mentre arriva lo streaming, quindi i token al secondo contano meno. Per un agentic workflow che aspetta la risposta completa prima del passo successivo, i token al secondo sono tutto. Di nuovo, la distribuzione conta: 80 tok/s costanti battono 50-150 tok/s variabili.
Se hai lavorato sulle prestazioni web (Core Web Vitals, punteggi Lighthouse), conosci la distinzione: quando qualcosa appare vs quando è utilizzabile. TTFT corrisponde a First Contentful Paint. Token al secondo corrisponde a Time to Interactive.
Capacità: Il provider può gestire il tuo volume? Limiti di rate, limiti di richieste concorrenti, se le prestazioni degradano su larga scala. Un provider potrebbe essere veloce per il tuo proof-of-concept ma limitarti in produzione.
Gestione del contesto: Le prestazioni reggono con input lunghi? Un prompt da 4K e uno da 64K hanno lo stesso prezzo per token, ma costano al provider importi molto diversi da servire. Alcuni provider rallentano drasticamente. Altri limitano. Altri addebitano di più.
Qualità: Stai ottenendo la precisione completa, o il provider sta silenziosamente eseguendo una versione compressa del modello per risparmiare memoria? Una precisione inferiore può significare output sottilmente peggiori, specialmente su compiti di ragionamento difficili o a lungo contesto.
Ogni provider fa compromessi tra questi cinque fattori, più il prezzo. Ottimizzare per uno spesso costa un altro. La domanda: quali compromessi si adattano al mio carico di lavoro?
Carichi di lavoro diversi, priorità diverse
I compromessi giusti dipendono interamente da cosa stai costruendo. Un chatbot e una pipeline di elaborazione batch hanno priorità opposte. Ottimizzare per uno danneggerebbe l'altro.
Una guida approssimativa su come i cinque fattori tipicamente si comportano. Il tuo caso d'uso specifico può differire (un chatbot con conversazioni molto lunghe si preoccupa più della gestione del contesto rispetto a uno tipico), ma questo ti dà un punto di partenza:
| Carico di lavoro | TTFT | Token/s | Capacità | Contesto | Qualità |
|---|---|---|---|---|---|
| Chat interattiva | ●●● | ● | ●● | ● | ●●● |
| Elaborazione batch | ● | ● | ●●● | ● | ●● |
| Agentic workflow | ● | ●●● | ●● | ●●● | ●●● |
| Voice AI / real-time | ●●● | ●●● | ●● | ● | ●●● |
| RAG / retrieval | ●● | ● | ● | ●●● | ●●● |
●●● = critico, ●● = importante, ● = meno importante
Esempio: agentic workflow. Un agent che effettua 50 chiamate di inferenza per completare un compito non si preoccupa molto del TTFT. Nessun umano sta guardando tra i passaggi. Ma i token al secondo si accumulano: se ogni chiamata genera 500 token, la differenza tra 100 tok/s e 30 tok/s è 5 secondi vs 17 secondi per chiamata. Su 50 chiamate, sono 4 minuti vs 14 minuti per lo stesso compito. Anche la gestione del contesto conta: le conversazioni degli agent crescono mentre lavorano, e i provider che rallentano a 32K+ token creeranno un collo di bottiglia nel tuo workflow.
Una volta che conosci il tuo carico di lavoro, puoi valutare correttamente. Ma prima, devi capire perché esistono questi compromessi.
Perché esistono questi compromessi
La maggior parte dei provider di inferenza gira su GPU, quindi i compromessi seguenti riflettono l'infrastruttura basata su GPU. Architetture alternative come i TPU di Google o i chip dataflow di SambaNova gestiscono alcuni di questi in modo diverso, ma le GPU rimangono la baseline del settore.
Prefill vs Decode: due problemi diversi
Quando invii una richiesta a un LLM, avvengono due fasi distinte:
Prefill (elaborazione del tuo input): Il modello legge l'intero prompt e capisce come ogni parola si relaziona a ogni altra parola (questo si chiama "attention"). Elabora tutti i token di input contemporaneamente, in parallelo. Le GPU eccellono in questo tipo di lavoro parallelo, operando ad alta utilizzazione.
Decode (generazione dell'output): Ora il modello produce token di output uno alla volta. I pesi risiedono nella memoria GPU, ma per ogni token la GPU deve leggerli per calcolare la prossima previsione. Il collo di bottiglia è la banda di memoria, non il calcolo. Le GPU restano inattive in attesa che i dati arrivino, scendendo a un'utilizzazione significativamente inferiore.
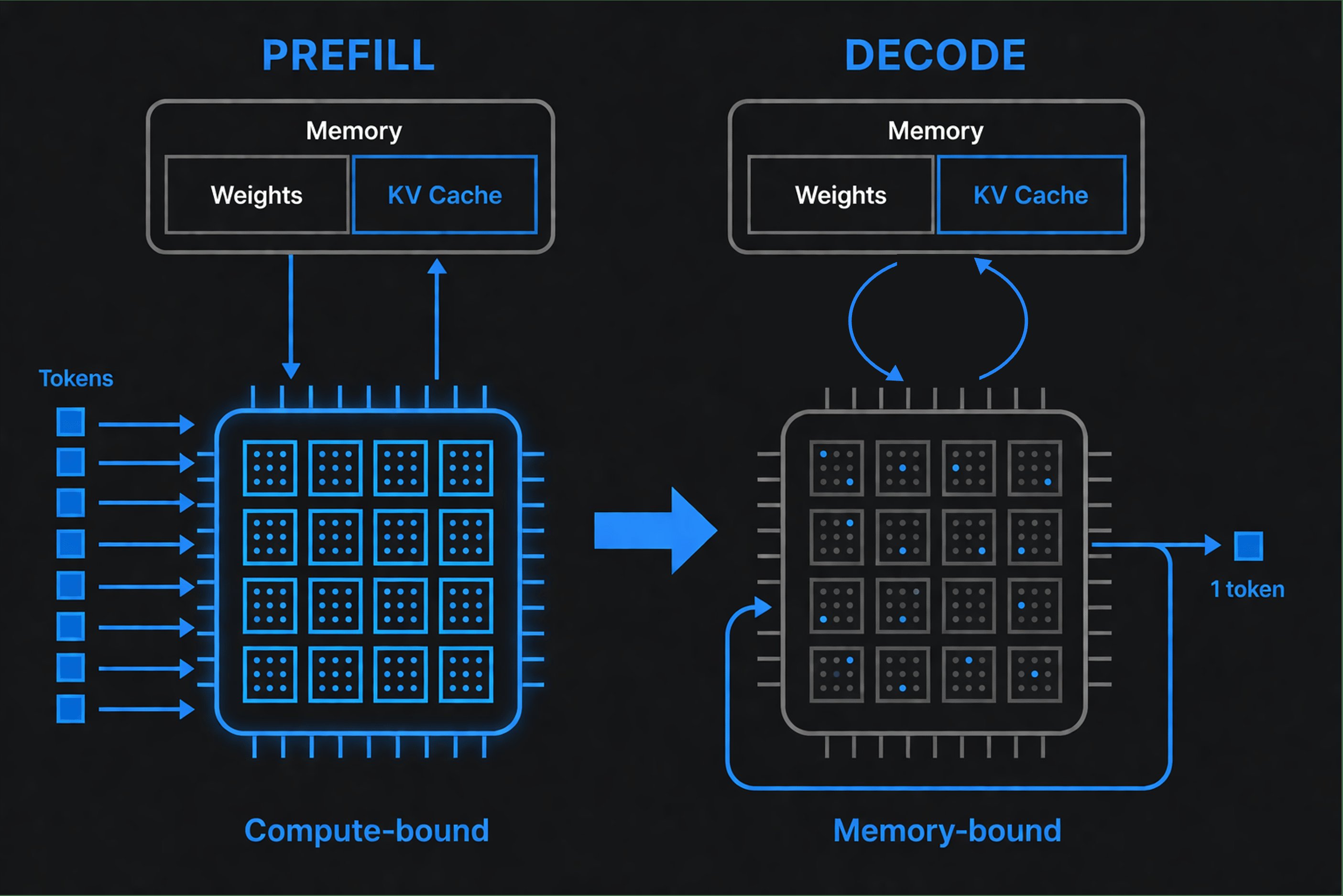
Questo crea due metriche separate:
- Time to First Token (TTFT): Quanto tempo prima che l'output inizi. Determinato dal prefill.
- Token al secondo: Quanto velocemente i token arrivano in streaming dopo. Determinato dal decode.
Un provider ottimizzato per il prefill mostra TTFT veloce ma potrebbe avere decode lento. Uno ottimizzato per il decode fa streaming veloce ma impiega più tempo a partire. Nessuno dei due è "migliore". Dipende dal tuo carico di lavoro.
Lunghezza del contesto: il moltiplicatore di costi nascosto
La maggior parte dei provider addebita la stessa tariffa per token indipendentemente dalla lunghezza del contesto. Ma il costo computazionale non è piatto.
Il prefill scala quadraticamente nell'attention standard del transformer. Il modello calcola come ogni parola si relaziona a ogni altra parola. Un prompt da 1.000 token significa 1 milione di calcoli di relazione. Un prompt da 10.000 token significa 100 milioni. Raddoppia il contesto, il calcolo dell'attention approssimativamente quadruplica. (Ottimizzazioni moderne come FlashAttention riducono questo in pratica, ma la pressione di scaling rimane.)
Numeri reali da Meta che esegue Llama 3 405B:
- 128K token: 3,8 secondi di prefill
- 1M token: 77 secondi di prefill
Anche il decode rallenta con il contesto. Durante la generazione, il modello memorizza calcoli intermedi in una "KV cache", un blocco note della conversazione finora. Questa cache cresce linearmente con il contesto. Una conversazione da 128K necessita di ~40 GB solo per la cache su un modello 70B.
Per ogni nuovo token, il modello legge l'intera cache. Cache più grande = più banda di memoria consumata = token al secondo più lenti. E poiché la memoria è condivisa tra utenti, cache più grandi significano meno utenti concorrenti.
Come gestiscono questo i provider? In tre modi:
- Sovvenzione incrociata: Gli utenti con contesto breve pagano per quelli con contesto lungo
- Prezzi a livelli: Google addebita 2x per contesti oltre 200K token
- Degradare il servizio: Limitare o deprioritizzare le richieste a lungo contesto
Se il tuo carico di lavoro è pesante di contesto, questo conta. Se sono prompt brevi, potresti star sovvenzionando altri.
Batching: come i provider scambiano i tuoi Token/s per la loro capacità
Cos'è il batching? Invece di elaborare una richiesta alla volta, i provider raggruppano più richieste e le elaborano simultaneamente. Più efficiente per la GPU. Come un autobus che trasporta 50 persone invece di 50 taxi.
Con batch size 1, le GPU hanno bassa utilizzazione perché aspettano la memoria. Con batch size 128, caricano i pesi del modello una volta ed elaborano tutte le 128 richieste insieme. Il provider può servire molti più utenti. Maggiore capacità.
Il problema: i tuoi token al secondo calano. Un modello che fornisce 400 tok/s a un singolo utente potrebbe fornire 30-50 tok/s per utente quando in batch con altri 127. Tutti aspettano tutti. (I sistemi moderni usano il continuous batching per ridurre questo compromesso, ma non lo eliminano.)
Per carichi di lavoro di elaborazione batch, questo va bene. Vuoi che il provider massimizzi la capacità; i token al secondo individuali non contano.
Per carichi di lavoro interattivi, questo è terribile. Al tuo utente non importa che il sistema abbia elaborato 10.000 richieste quel secondo. Gli importa che la sua risposta abbia impiegato 3 secondi.
Quando un provider cita "richieste al secondo" o "token al secondo", chiedi: è la capacità totale del sistema, o i token al secondo che ogni utente sperimenta? Sono numeri molto diversi.
Quantizzazione: la precisione che non ti dicono
Cos'è la quantizzazione? I modelli AI memorizzano la conoscenza come miliardi di numeri ("pesi"). Questi possono essere memorizzati a diversi livelli di precisione, come misurare con millimetri vs centimetri. Una precisione inferiore risparmia memoria ma può degradare la qualità dell'output.
| Precisione | Risparmio memoria | Impatto qualità |
|---|---|---|
| FP16/BF16 | Baseline | Nessuno (la maggior parte dei modelli si addestra a questo) |
| FP8 | ~50% | Minimo (<1% perdita di accuratezza) |
| INT8 | ~50% | Minore (99%+ accuratezza preservata) |
| INT4 | ~75% | Significativo su compiti impegnativi |
FP8 e INT8 sono quasi invisibili per la maggior parte dei carichi di lavoro. INT4 è dove possono emergere problemi: la ricerca mostra fino al 59% di perdita di accuratezza su compiti a lungo contesto e 69,8% di degradazione sul ragionamento difficile nei casi peggiori. L'impatto varia molto per compito; molte applicazioni reali vedono cali molto più piccoli, ma il ragionamento a lungo contesto è particolarmente sensibile.
La maggior parte dei provider non pubblicizza il proprio livello di quantizzazione. Alcuni regolano dinamicamente la precisione in base al carico: precisione completa alle 2 di notte, quantizzato nelle ore di punta. Stesso prezzo, prodotto diverso.
Per l'elaborazione batch, una quantizzazione aggressiva potrebbe essere accettabile. Stai ottimizzando i costi; piccoli cali di accuratezza sono tollerabili.
Per applicazioni di produzione, devi sapere quale precisione stai ottenendo.
Perché i token di output costano di più
La maggior parte dei provider addebita 4-6x di più per i token di output rispetto agli input:
| Provider | Input €/M | Output €/M | Rapporto |
|---|---|---|---|
| OpenAI GPT-5.4 | €2.30 | €13.80 | 6x |
| Anthropic Claude Opus 4.6 | €4.60 | €23.00 | 5x |
| Google Gemini 3.1 Pro | €1.84 | €11.00 | 6x |
| DeepSeek V3.2 | €0.13 | €0.26 | 2x |
Source, convertito a ~€0,92/$
Perché? Ricorda la differenza prefill vs decode: l'elaborazione dell'input tiene la GPU occupata, la generazione dell'output no. Il moltiplicatore riflette approssimativamente le differenze nell'efficienza della GPU tra elaborazione di input e output.
Nota DeepSeek a 2x. DeepSeek combina MoE (671B parametri, solo 37B attivi) con attention sparsa che riduce il calcolo a lungo contesto. V4, rilasciato ad aprile 2026, spinge questo ancora oltre. L'architettura cambia l'economia.
I carichi di lavoro pesanti di input (RAG, prompt lunghi, risposte brevi) beneficiano di questa divisione. I carichi di lavoro pesanti di output (generazione di codice, creazione di contenuti) vengono colpiti dal moltiplicatore 4-6x.
Valutare i provider per il tuo carico di lavoro
Armato di questo, puoi fare le domande giuste.
Per carichi di lavoro interattivi / rivolti all'utente:
"Qual è il vostro TTFT p50 e p99 alla mia lunghezza di contesto?"
I benchmark a riposo non contano. Chiedi numeri sotto carico.
Segnale d'allarme: hanno solo benchmark sintetici.
"Quanti token al secondo per utente?"
Token al secondo in streaming verso ogni utente, non capacità totale del sistema.
Segnale d'allarme: citano numeri "fino a" o metriche di sistema.
Per elaborazione batch:
"Qual è la vostra capacità massima sostenuta?"
Token totali all'ora che puoi far passare.
Segnale d'allarme: non sanno separare le metriche di capacità dalla velocità per utente.
"A quale precisione servite ad alto volume?"
INT4 su scala potrebbe andare bene per il tuo caso d'uso.
Segnale d'allarme: non vogliono rivelare i livelli di quantizzazione.
Per agentic / long-context workload:
"Quanti token al secondo a 32K, 64K, 128K di contesto?"
Gli agentic workflow aspettano risposte complete. I token al secondo a lungo contesto sono critici.
Segnale d'allarme: citano solo TTFT, o non hanno dettagli per lunghezza di contesto.
"Come degradano le prestazioni sotto richieste concorrenti a lungo contesto?"
Il contesto lungo consuma memoria che potrebbe servire altri utenti. Cosa succede su scala?
Segnale d'allarme: non sanno di cosa stai parlando.
Per voice / real-time:
"Qual è la vostra latenza end-to-end per speech-to-text → LLM → text-to-speech?"
Sotto i 500ms o non è real-time.
Segnale d'allarme: citano solo la latenza LLM, non la pipeline completa.
Perché questo conta adesso
L'era dell'AI a tariffa fissa, all-you-can-eat sta finendo.
GitHub ha recentemente spostato Copilot alla fatturazione basata sull'utilizzo. Anthropic sta restringendo i limiti degli abbonamenti Claude man mano che l'utilizzo agentic supera ciò per cui i piani a tariffa fissa erano stati costruiti. Questi cambiamenti a livello di applicazione riflettono la realtà sottostante: l'inferenza costa denaro, e più token consumi, più costa servirti. Man mano che i sussidi che finanziavano i piani illimitati svaniscono, capire cosa stai realmente comprando a livello di inferenza diventa più importante, non meno.
Alcuni provider ora lo rendono esplicito - i livelli Flex vs Priority di Google, i prezzi a livelli di Amazon Bedrock - riconoscendo che la velocità stessa ha valore. E questi compromessi si intensificano con modelli più grandi: i modelli a trilioni di parametri non possono stare su una singola GPU e richiedono parallelizzazione complessa, rendendo l'inferenza ad alta velocità ancora più difficile da fornire.
I provider che competono solo sul prezzo taglieranno angoli che non puoi vedere: quantizzazione, batching, throttling. Quelli che competono sulle metriche che contano per il tuo carico di lavoro addebiteranno di più, e ne varranno la pena.
Smetti di confrontare il prezzo per milione di token. Inizia dai cinque fattori e trova i compromessi che si adattano al tuo carico di lavoro.
Infercom pubblica benchmark in tempo reale su infercom.ai/performance se vuoi confrontare queste metriche tu stesso.
Scritto da Thomas Vits, con assistenza dell'AI.
Fonti
Benchmark & Prestazioni
- DeepInfra: DeepSeek V3.2 API Benchmarks
- MLCommons MLPerf Inference v5.0
- Artificial Analysis LLM Leaderboard
Architettura & Calcolo
- Meta Engineering: Scaling LLM Inference
- Prefill Is Compute-Bound, Decode Is Memory-Bound
- NVIDIA: KV Cache Offloading
- Transformer FLOPs Analysis
Quantizzazione
- Red Hat: vLLM FP8 Benchmarks
- Red Hat: Half Million Evaluations on Quantized LLMs
- EMNLP 2025: INT4 Long-Context Degradation
- COLM 2025: Quantization Impact on Reasoning