Insights
Approfondimenti tecnici, analisi di settore e prospettive sull'inferenza AI dal team Infercom.
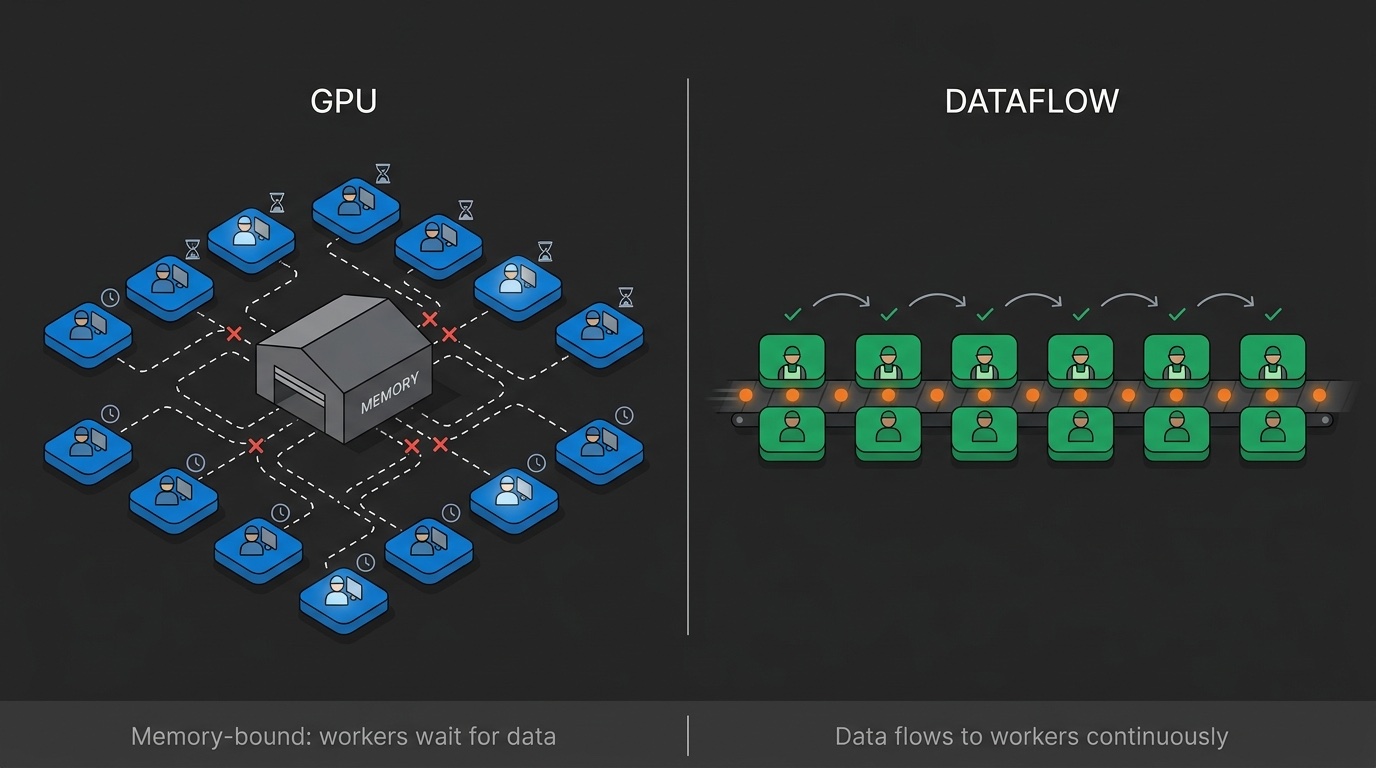
713 Token al Secondo: L'Architettura Dietro Ultraspeed
Perché l'architettura dataflow supera le GPU per l'inferenza LLM. Spiegazione tecnica dei colli di bottiglia della memoria, dell'esecuzione spaziale e del problema di decode.
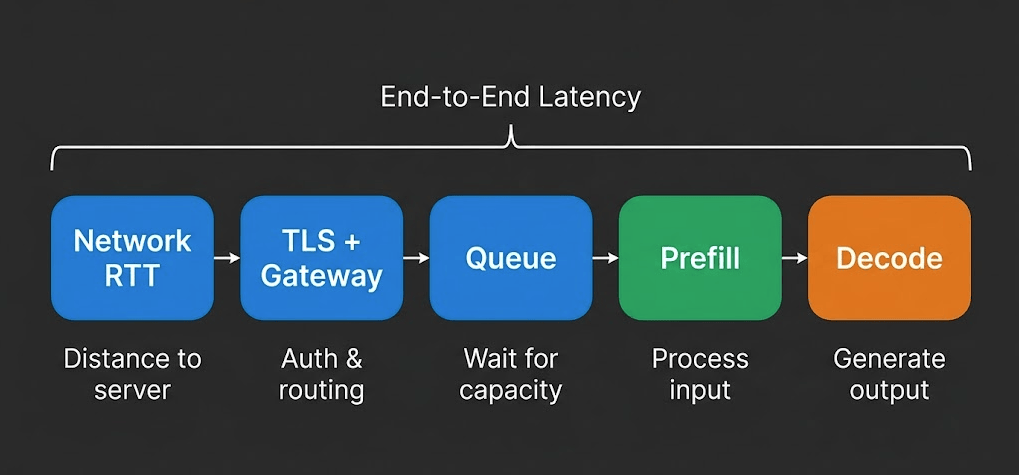
Velocità di inferenza LLM spiegata: TTFT, throughput e cosa conta davvero
Quando un provider pubblicizza 400 tok/s e un altro afferma latenza sotto 200ms, stanno misurando cose diverse. Scopri quali metriche contano per il tuo workload.

Velocità di Inferenza nell'Agentic Coding: Perché il Throughput dei Token è Importante
Gli strumenti di agentic coding consumano 500K-2M token per sviluppatore al giorno. Questo articolo spiega perché la velocità di inferenza è importante e come configurare strumenti come Cursor, Cline e Codex CLI per un throughput più elevato.
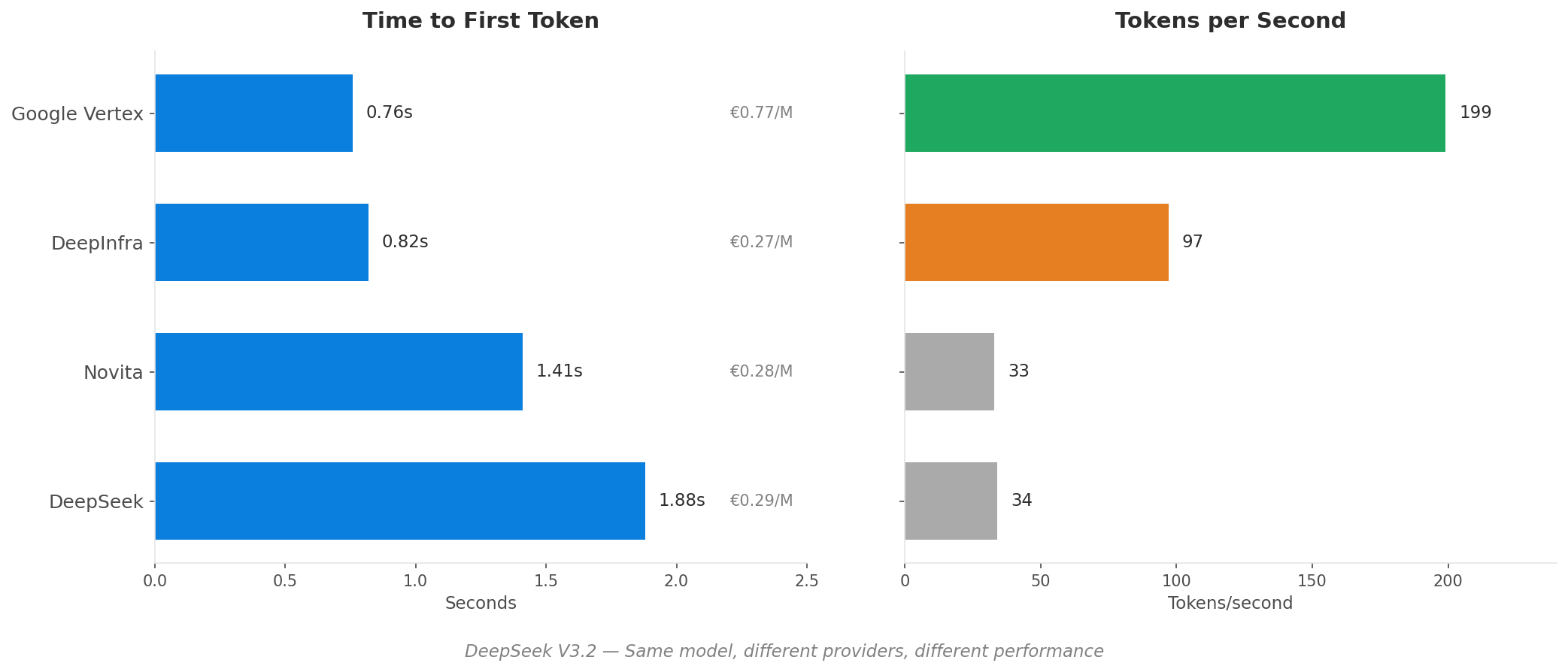
Cosa non ti dice il 'Prezzo per Token'
Se stai confrontando i fornitori di inferenza AI solo in base al prezzo per token, ti stai perdendo i fattori che determinano effettivamente costi e prestazioni.