Cosa accade in ciascuna fase
Durante il prefill, il modello legge l'intero prompt in una volta - un grande calcolo matrice-matrice altamente parallelo che satura di fatto le unità di calcolo dell'hardware. Il risultato è la KV-cache: le chiavi e i valori di attention per ogni token del prompt, calcolati una volta e riutilizzati per il resto della richiesta. Il prefill termina quando viene prodotto il primo token di output, motivo per cui la lunghezza del prompt determina il Time to First Token.
Durante il decode, il modello genera un token, lo aggiunge al contesto e ripete. Ogni step è una sottile operazione matrice-vettore che riutilizza lo stato in cache - ma deve trasferire in streaming i pesi del modello dalla memoria per ogni singolo token. Questa fase è memory-bound: la velocità con cui pesi e dati della cache si muovono dalla memoria domina la latenza, non l'aritmetica.
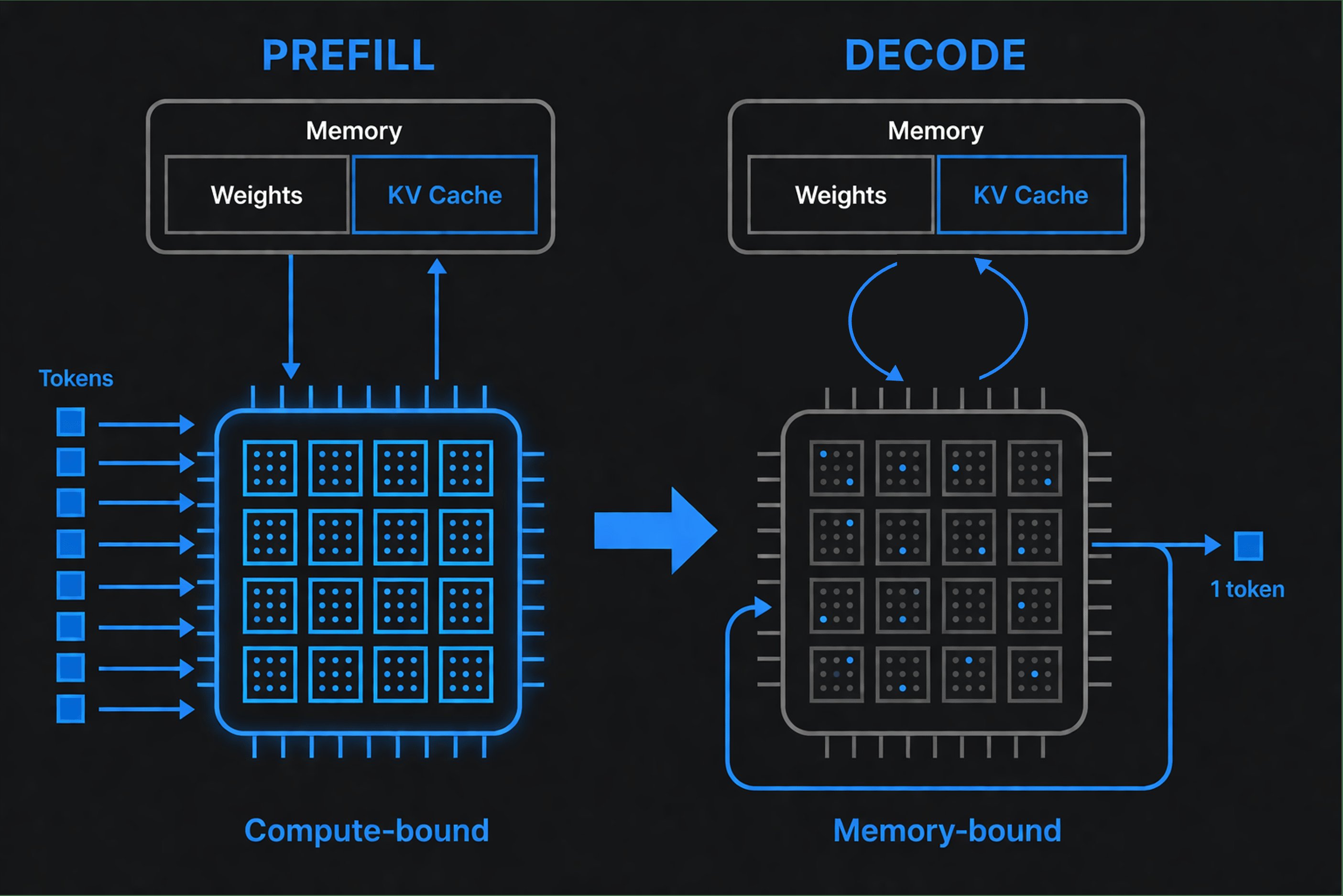
Perché la distinzione è importante
Le due fasi vogliono hardware diverso. Il prefill premia il calcolo puro; il decode premia la larghezza di banda della memoria e il movimento efficiente dei dati. La guida ingegneristica di Databricks fa l'osservazione pratica: la larghezza di banda della memoria è un predittore migliore della velocità di generazione dei token rispetto alle prestazioni di calcolo di picco. Un chip con FLOPS spettacolari può comunque generare token lentamente se si blocca sulla memoria.
Questo è anche il motivo per cui il serving basato su GPU si appoggia pesantemente al batching: ammortizzare ogni caricamento dei pesi su molte richieste concorrenti recupera l'utilizzazione durante il decode - al costo della velocità per utente. Le architetture progettate attorno al movimento dei dati, come l'hardware dataflow che utilizziamo, attaccano invece direttamente il collo di bottiglia del decode, mantenendo alta l'utilizzazione anche a batch size bassi.
Leggere le metriche attraverso questa lente
Le prestazioni di prefill si manifestano come TTFT; le prestazioni di decode si manifestano come latenza inter-token e token al secondo in output. Una precisazione dalla letteratura di ricerca: la divisione compute-bound/memory-bound vale ai batch size di serving comuni - a batch size molto grandi il decode può spostarsi verso il compute-bound. La tendenza del settore al serving disaggregato - eseguire prefill e decode su pool di hardware separati e specializzati - esiste proprio perché le due fasi sono così diverse.
Fonti
Letture correlate
Termini correlati
TTFT (Time to First Token)
Quanto tempo un utente attende tra l'invio di una richiesta e la visualizzazione del primo token della risposta.
Latenza Inter-Token (ITL)
L'intervallo medio di tempo tra token consecutivi durante la generazione - chiamato anche TPOT.
Architettura Dataflow
Il modello di esecuzione in cui i dati fluiscono attraverso le operazioni come una pipeline - eliminando i round-trip kernel per kernel dell'esecuzione su GPU.
Context Window
La quantità massima di testo, in token, che un modello può considerare in una volta - prompt più output. La sua lunghezza plasma direttamente velocità e costo dell'inferenza.
Scopri come l'architettura dataflow di SambaNova cambia l'economia dell'inferenza - e perché abbiamo costruito su di essa.